LLM 기반 고객 Agent를 활용한 추천시스템 시뮬레이션 (Part 1. 논문 리뷰)

0
431
리뷰 동기
인과추론 기반 추천시스템 관련 논문을 탐색하던 중, 고객의 동조 정도를 고객 프로필에 반영한 본 논문을 접하게 되었습니다. 이전 세미나에서 리뷰했던 DICE 모델은 동조 임베딩과 관심사 임베딩을 통해 고객의 관심사와 인기도 반응을 더욱 정밀하게 학습하여 모델 성능을 향상시켰습니다.
본 논문은 인과추론 개념을 이용해 고객의 동조 효과를 고객 프로필에 반영하는 모듈을 구축하였으며, 단순 고객 정보를 RAG로 활용하는 기존 시스템과 차별점을 보입니다.
추천시스템 접근 방식 또한 단순 시청 이력뿐 아니라, 시스템 진입 단계별 노출을 가정한 시뮬레이션 설계를 통해 보다 현실적인 모델 구축에 기여할 수 있음을 보여줍니다.
결과 분석에서는 필터 버블 현상과 인과관계가 다루어져, 리뷰와 코드 분석 후 실제 추천시스템 개발에 적용할 만한 요소들이 많아 이 논문을 선택하게 되었습니다.

개요
- 추천 시스템 연구에서 LLM 기반의 Generative Agents를 이용해 실제 사용자 행동을 시뮬레이션하는 플랫폼(Agent4Rec)을 제안함.
- 사용자 프로필, 기억, 액션 모듈을 활용하여 사용자 행동과 인지적 특성을 효과적으로 모사하는 시뮬레이터 구축이 목적임.
Introduction
기존 추천시스템의 문제점
- 기존 추천 시스템 평가 방식은 오프라인과 온라인 성능이 크게 달라 연구와 현실 간의 괴리가 큼.
- 오프라인 평가와 실제 사용자 경험 사이에 괴리 (이력은 결과?)
- 기존 시뮬레이터는 사용자의 감정이나 인지적 요소를 충분히 반영하지 못함.
제안
- 실제 사용자의 행동을 정교하게 모방할 수 있는 LLM을 활용한 생성형 Agent 기반 사용자 시뮬레이터 Agent4Rec 제안.
- 사용자 특성(Social traits), 취향, 정서적 기억을 통합하여 보다 현실에 가까운 사용자 행동을 시뮬레이션함.
- 필터 버블 효과 재현 및 인과 관계 탐색과 같은 복잡한 문제를 실험할 수 있는 환경 제공.
AGENT4REC

Agent Architecture(Red)
사용자 프로필(Profile Module)
- 실제 데이터를 바탕으로 사용자의 고유한 취향과 사회적 특성을 초기화하는 역할을 함.
- 사용자의 행동 특성을 나타내는 3가지 주요 사회적 특성(활동성, 동조성, 다양성)을 정의하고, 사용자의 과거 시청 기록과 평가 점수를 이용하여 개인의 선호 프로필을 생성함.
- 활동성(Activity): 사용자가 추천된 아이템과 얼마나 자주 상호작용하는지를 나타냄.
- 동조성(Conformity): 사용자의 평가가 평균 아이템 평가와 얼마나 유사한지 측정하여, 사용자가 대중적인 의견과 얼마나 일치하는지를 나타냄.
- 다양성(Diversity): 사용자가 얼마나 다양한 장르의 아이템과 상호작용하는지를 나타냄.
메모리 모듈(Memory Module)
- 에이전트의 행동을 보다 현실적으로 모사하기 위해 사용자 기억을 사실적 기억(Factual memory)과 감정적 기억(Emotional memory)으로 나누어 기록하고 관리함.
- 사실적 기억: 에이전트가 어떤 아이템과 상호작용했는지, 그 아이템에 대해 내린 평가와 구체적인 행동을 기록함.
- 감정적 기억(Emotional memory): 상호작용 과정에서 느낀 사용자의 감정(만족, 피로감 등)을 기록하여, 에이전트가 감정 기반으로 행동하고 스스로의 상태를 반영할 수 있도록 함.
-
자연어 묘사(for human)와 임베딩(main)으로 메모리 저장
-
기억 검색(Memory Retrieval):
에이전트가 현재의 상황에서 가장 연관된 기억을 검색하여, 과거의 사실적 및 감정적 기억을 기반으로 현재 상황에 적합한 행동을 취할 수 있도록 지원합니다.
-
기억 기록(Memory Writing):
에이전트가 수행한 행동과 그에 따른 감정적 반응을 자연어 형태로 기록하여, 추후 행동과 의사결정에 참고할 수 있는 경험 데이터를 지속적으로 저장합니다.
-
감정 기반 자기반성(Memory Reflection):
에이전트가 일정 행동 후 자신의 만족도와 피로감을 스스로 평가하여 이후 행동을 결정하게 하는 자기 성찰 과정을 지원합니다.
-
행동 모듈(Action Module)
- 취향 기반 행동
- 프로필에 맞는 아이템 시청 선택
- 시청한 아이템 평가 및 감상 표현
- 감정 기반 행동
- 이전 경험을 바탕으로 만족도 및 피로감 평가
- 시스템 계속 사용 또는 종료 결정
- 종료 후 추천 시스템 만족도 평가 인터뷰 진행
Recommendation Environment(Blue)
아이템 프로필 생성 (Item Profile Generation)
- 추천 대상 아이템을 실제 사용자들이 느끼는 특징과 유사하게 구성하기 위해 품질(과거 사용자 평점 기반), 인기(평가 수 기반), 장르, 줄거리 등 다양한 속성을 설정함
- 장르 및 줄거리는 대형 언어 모델(LLM)을 통해 아이템 제목만을 이용하여 생성하며, 특히 LLM의 Few-shot 분류를 이용해 정확한 장르 분류 여부를 체크하여, 신뢰도와 정확성을 높이고 허위 생성(환각, hallucination) 위험을 최소화하기 위해 장르가 잘못 분류된 아이템은 제외하는 방식으로 신뢰성을 유지함
- 아이템 프로필:
- 품질(Quality): 아이템이 받은 과거 사용자 평가 기반으로 계산
- 인기(Popularity): 사용자들의 평가 수나 시청 횟수를 바탕으로 측정
- 장르(Genre) 및 줄거리(Summary): LLM이 아이템 제목만을 사용해 생성하며, 정확도 검증 후 사용
페이지 단위 추천(Page-by-Page Recommendation)
- 실제 추천 서비스 환경(예: 넷플릭스, 유튜브 등)을 모방하여 아이템을 여러 페이지로 나누어 제공함
- 사용자는 매 페이지마다 추천된 아이템과 상호작용(시청, 평가, 피드백 등)을 수행하고, 이를 바탕으로 사용자의 다음 페이지 추천 결과가 점점 개인화되어 가는 구조임
- 이 과정에서 실시간으로 사용자 만족도와 행동 데이터를 수집하여 추천 알고리즘 재학습에 활용할 수 있음
추천 알고리즘 설계(Recommendation Algorithm Designs)
- 시뮬레이터는 기본적으로 다양한 협업 필터링 기반 알고리즘(MF, LightGCN, MultVAE)을 제공함
- Random, Most Popular와 같은 기초적인 알고리즘부터 Matrix Factorization(MF), 그래프 기반 추천 모델(LightGCN), Variational Autoencoder(MultVAE) 등 여러 알고리즘을 미리 구현하여 비교 분석이 가능함
- 별도의 추천 알고리즘을 쉽게 추가할 수 있도록 확장 가능한 인터페이스를 설계하여, 연구자나 실무자들이 다양한 알고리즘을 자유롭게 테스트하고 평가할 수 있게 함
Agent Alignment Evaluation
에이전트가 추천 시스템 연구에 얼마나 현실적이고 유용한지를 다양한 관점에서 종합적으로 평가
사용자 취향 일치도(User Taste Alignment)
- 평가 목적
- LLM 기반 생성적 에이전트가 실제 인간의 행동을 얼마나 현실적으로 모사할 수 있는지 검증
- 평가 방식
- 실제 사용자의 취향과 일치하는 아이템을 얼마나 잘 선택하는지 평가
- MovieLens-1M, Steam, Amazon-Book 데이터셋을 이용하여 평가 수행
- 주요 관찰 결과
- 에이전트는 사용자의 실제 선호도를 일관되게 높은 정확도와 리콜(Accuracy 약 65%, Recall 약 75%)로 반영함. (아래 문제가 있지만 신뢰할 수 있을 만한 수준임 a.k.a 현실과 매우 유사)
- 반면 Precision과 F1 점수는 추천 아이템 비율이 낮아질수록 급격히 하락하는 경향을 보임.
- 선호 아이템 수가 적은 경우에도 매번 일정한 수를 선택하려고 함
- 이러한 현상은 LLM의 내재적 환각(hallucination) 현상 때문으로 분석됨.
- 선호도 보다는 특정 아이템을 선택하려는 현상
- 전체 점수 분포도
- 에이전트가 현실 사용자처럼 다양한 사회적 특성(예: 활동성, 동조성, 다양성)을 표현하는지를 분석하여 실제 사용자 데이터와의 일치 정도를 측정합니다.
- 실제 점수 분포 vs 시뮬레이션 점수 분포

소셜 특성 정합도(Social Traits Alignment)
- 실제 추천 환경에서는 사용자 행동이 단순한 개인 취향뿐 아니라 활동성, 동조성, 다양성과 같은 사회적 특성에 의해서도 영향을 받음.
- Agent4Rec은 이러한 사회적 특성을 반영하기 위해, MovieLens 통계를 기반으로 각 사용자 프로필에 대해 활동, 동조, 다양성 세 가지 특성을 고, 중, 저 세 등급으로 분류하여 에이전트를 구성함.
- 같은 취향을 가진 에이전트라도 사회적 특성에 따라 서로 다른 행동 패턴을 보일 수 있음을 가정함.
- 평가 및 결과 (Results)
- 행동 차이 검증:
- 서로 다른 사회적 특성 등급을 가진 에이전트들이 서로 구분되는 행동 패턴을 보이는지 확인
- 각 행동별 티어를 프롬프트에 넣었는데 의도대로 행동 스코어가 나옴
- 행동 차이 검증:

- Ablation 실험:
- 사회적 특성을 포함한 프로필과 그렇지 않은 경우를 비교하여, 사회적 특성이 에이전트 행동에 미치는 영향을 검증
- 활동성 프롬프트 추가 vs 제거의 결과 비교
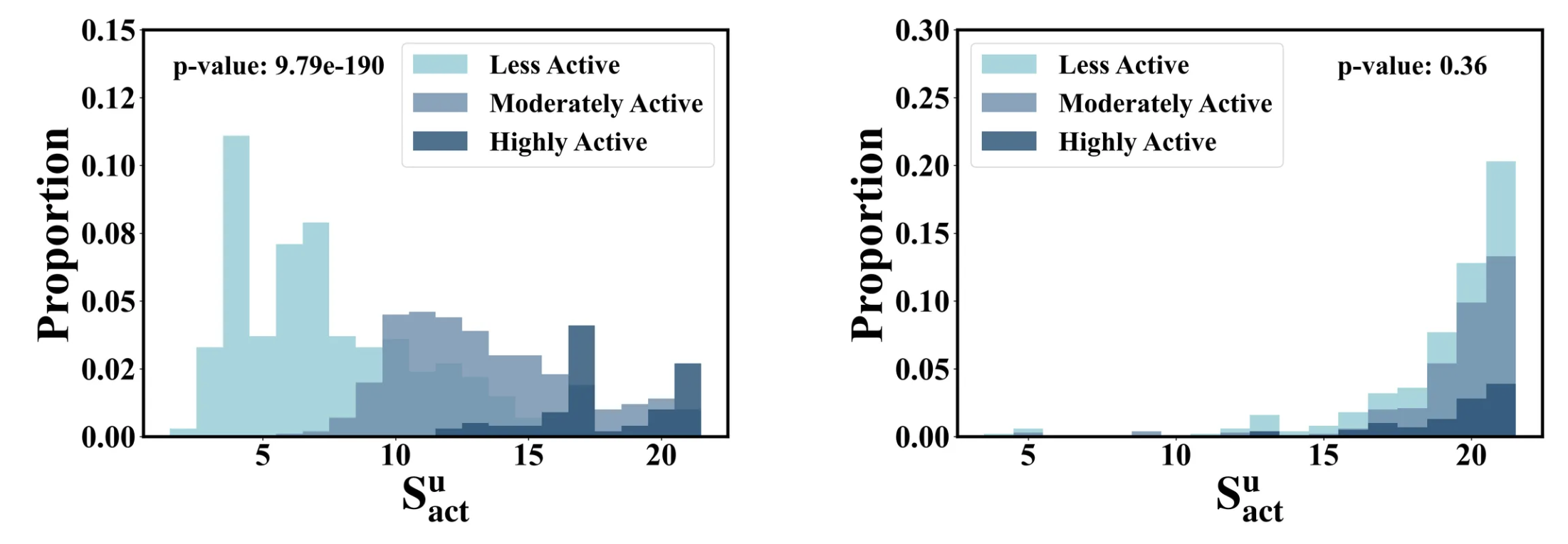
- 분포 일치도:
- 시뮬레이션된 사회적 특성 분포가 실제 사용자 데이터와 얼마나 유사한지를 확인.
- 다양성 실제 vs 시뮬레이션
- 결론:
- 광범위한 분포 분석, ablation 실험, 통계적 검증 결과, 사회적 특성은 에이전트 행동의 현실성을 높이는 데 중요한 역할을 함.
- 단, 다양성 특성의 경우, MovieLens 데이터의 영화 카테고리 중복으로 인해 구별이 미미할 수 있으므로, 다른 데이터셋으로 추가 검증이 필요함.
추천 전략 평가(Recommendation Strategy Evaluation)
- 실제 사용자들은 추천 알고리즘에 따라 만족도가 다르게 나타나며, 고급(SOTA) 알고리즘일수록 높은 만족도를 보임
- 생성형 에이전트가 실제 인간의 행동을 모사할 수 있다면, 이 에이전트들도 인간과 유사하게 알고리즘에 따른 만족도 차이를 보여야 한다는 가정 하에 평가를 진행
- 실험 설정 (Setting)
- 협업 필터링 기반의 다양한 추천 전략(랜덤, 인기순, MF, LightGCN, MultVAE)을 사용하여 MovieLens 데이터셋에서 시뮬레이션을 수행
- 각 추천 페이지에 4개의 영화가 제시되며, 에이전트는 개인 취향에 따라 아이템을 시청하고 평가
- 에이전트는 추천 페이지에 대한 만족도를 바탕으로 다음 페이지로 넘어갈지, 시스템을 종료할지를 결정하며, 최대 5페이지까지 탐색 후 종료
- 종료 시 에이전트는 추천 시스템에 대한 만족도를 1에서 10까지의 점수로 평가
- 평가 지표로 평균 시청 비율, 평균 좋아요 수, 평균 좋아요 비율, 평균 종료 페이지 수, 평균 만족도 점수 등 여러 관점에서 다각도로 측정
- 평가 결과 (Results)
- 알고리즘 기반의 추천이 랜덤이나 인기순 추천보다 에이전트의 만족도를 높게 반영함
| Model | P̄_view | N̄_like | P̄_like | N̄_exit | S̄_sat |
|---|---|---|---|---|---|
| Random | 0.312 | 3.3 | 0.269 | 2.99 | 2.93 |
| Pop | 0.398 | 4.45 | 0.360 | 3.01 | 3.42 |
| MF | 0.488 | 6.07* | 0.462 | 3.17* | 3.80 |
| MultVAE | 0.495 | 5.69 | 0.452 | 3.10 | 3.75 |
| LightGCN | 0.502* | 5.73 | 0.465* | 3.02 | 3.85* |
- 특히, LightGCN이 MF와 MultVAE보다 우수한 성능을 보이는 결과가 확인되어, 이는 실제 사용자 경험과 일치하는 경향을 보여줌
- 이러한 결과는 LLM 기반의 생성적 에이전트가 추천 전략의 미세한 차이를 평가할 수 있는 능력이 있음을 입증하며, 비용 효율적인 온라인 A/B 테스트 대안으로 활용될 가능성을 제시함
페이지 단위 추천 개선 평가(Page-by-Page Recommendation Enhancement)
- 실제 추천 플랫폼에서는 사용자 행동 데이터를 실시간으로 수집해, 이를 바탕으로 추천 알고리즘을 점진적으로 개선함
- 페이지별 추천 설정은 이러한 피드백 기반 개선 과정을 시뮬레이션하여, 사용자의 최신 선호도를 정확히 반영하려는 목표를 가짐
- 설정 (Setting)
- 시뮬레이션 종료 후, 각 에이전트가 시청한 영화와 시청하지 않은 영화를 모두 수집
- 이 데이터를 긍정 신호로 사용하여 사용자별 학습 데이터에 추가, 추천 알고리즘을 재학습
- 재학습된 모델은 Recall@20, NDCG@20과 같은 오프라인 평가 지표 및 N¯exit, S¯sat 등 만족도 평가를 통해 성능이 측정됨
- 결과 (Results)
- 에이전트가 시청한 영화를 데이터에 포함시킨 경우, 모든 추천 알고리즘에서 오프라인 지표와 만족도 평가가 개선됨
- 반면, 시청하지 않은 영화를 추가하면 전체 사용자 경험이 저하되는 결과가 나타났다.
- 노출되었으나 시청하지 않은 아이템은 부정적인 영향을 끼침
| MF | MultVAE | LightGCN | |||
|---|---|---|---|---|---|
| Offline | Recall | NDCG | Recall | NDCG | Recall |
| Origin | 0.1506 | 0.3561 | 0.1609 | 0.3512 | 0.1757 |
| + Unviewed | 0.1523 | 0.3557 | 0.1598 | 0.3487 | 0.1729 |
| + Viewed | 0.1570* | 0.3604* | 0.1613* | 0.3540* | 0.1765* |
| Simulation | N¯exit | S¯sat | N¯exit | S¯sat | N¯exit |
| Origin | 3.17 | 3.80 | 3.10 | 3.75 | 3.02 |
| + Unviewed | 3.03 | 3.77 | 3.01 | 3.77 | 3.06 |
| + Viewed | 3.27* | 3.83* | 3.18* | 3.87* | 3.10* |
- 에이전트의 영화 선택(시청한 영화)이 사용자의 고유 선호를 신뢰할 수 있게 나타내는 좋은 지표임을 확인 가능
- 반면, 시청하지 않은 영화를 긍정 신호로 넣으면, 부정적인 피드백(실제로는 사용자가 관심 없었던 항목)을 오해하게 되어, 추천 품질이 떨어짐
감정 기반 인터뷰 분석(Case Study of Feeling Interview)
- 추천 사용 경험을 마친 에이전트가 진행한 인터뷰를 분석해, 시스템에 대한 만족도, 피로도, 사용 종료 이유 등 심층적인 정서적 요소까지 평가하여 실제 사용자 평가의 현실성을 높이는 데 기여합니다.
- 전통적인 추천 시뮬레이터와 달리, LLM 기반 에이전트 시뮬레이션은 인간이 이해할 수 있는 설명이 가능함
- 에이전트로부터 설명을 이끌어내면 시뮬레이션 결과의 신뢰성을 평가하고, 추천 시스템을 더욱 정교하게 개선할 수 있음
- 결과 (Results)
- MovieLens 데이터셋을 대상으로 한 종료 후 인터뷰 사례에서, 에이전트는 추천된 영화에 대해 개인 취향, 사회적 특성, 감정적 기억을 기반으로 평가를 내렸다.
- 예시
- 에이전트는 추천 시스템이 자신의 선호에 부합하는 영화를 제시했다고 평가했지만, 다양한 관심에도 불구하고 시스템이 인기 영화 위주로 추천하는 점에 대해서는 만족도가 낮게 나타났다.
- 에이전트는 추천 시스템에 대해 1-10점 척도로 6점을 부여함.
- 개인 취향과 이전 평점을 반영해 맞는 영화도 추천했으나, 불만족스러운 추천도 존재함.
- Balanced Evaluator: 개인 선호와 역사적 평점을 고려한 점은 긍정적으로 평가됨.
- Occasional Viewer: 평소 영화 추천에 쉽게 영향을 받지 않으며, 오직 자신의 취향에 딱 맞는 영화만 선호함.
- Cinematic Trailblazer: 독특하고 희귀한 영화를 선호하지만, 추천은 주로 인기 클래식에 치우침.
- 전체적으로 시스템에는 강점이 있으나, 영화 감상 경험을 완전히 만족시키지 못함.
- 에이전트는 추천 시스템이 자신의 선호에 부합하는 영화를 제시했다고 평가했지만, 다양한 관심에도 불구하고 시스템이 인기 영화 위주로 추천하는 점에 대해서는 만족도가 낮게 나타났다.

Insights and Exploration
Agent4Rec의 시뮬레이션 능력을 바탕으로 추천 분야의 미해결 문제에 대한 통찰력을 제공할 수 있는지를 탐구
Filter Bubble Effect
- 추천 시스템에서는 알고리즘 기반 피드백 루프로 인해 추천 콘텐츠가 점점 유사해지는 필터 버블 현상이 존재함
- 본 연구에서는 Agent4Rec이 이 필터 버블 현상을 얼마나 잘 재현하는지 평가함
- 실험 설정 (Setting)
- MovieLens의 영화 풀을 네 부분으로 균등하게 나누어, MF 기반 추천 알고리즘을 4회 시뮬레이션에 걸쳐 평가.
- 각 시뮬레이션 라운드에서 추천은 최대 5페이지까지 제공되며, 라운드마다 MF 추천 모델이 재학습됨.
- 평가 지표로:
- P¯top1-genre: 추천된 영화 중 가장 많이 차지하는 장르의 비율
- N¯genres: 추천된 영화에 포함된 장르의 평균 개수
- 결과 (Results)
- 시뮬레이션 라운드가 반복됨에 따라, 추천 콘텐츠가 점점 특정 장르에 집중되는 경향이 나타났다.
- 즉, N¯genres(장르 다양성)는 감소하고, P¯top1-genre(최다 장르 비율)는 증가하였다.
- 이러한 결과는 Agent4Rec이 실제 추천 시스템에서 관찰되는 필터 버블 현상을 잘 반영하고 있음을 보여준다.

Discovering Causal Relationships

- 인과 관계 발견은 관측 데이터를 기반으로 인과 구조(인과 그래프)를 추론하는 기법으로, 특정 분야의 근본 메커니즘을 이해하는 데 중요함
- 추천 시뮬레이터를 활용하면 데이터 수집과 잠재적 혼란 요인(confounding issues) 해결에 도움이 될 수 있으므로, Agent4Rec이 추천 시스템에서 인과 관계를 밝혀내는 데 기여할 수 있는지를 탐구함
-
설정 (Setting)
- MovieLens에서 각 영화에 대해 에이전트가 시뮬레이션한 평점 외에도, 영화 품질, 영화 인기, 노출률, 시청 횟수 등 네 가지 주요 변수를 수집
- 이 데이터를 바탕으로 DirectLiNGAM 알고리즘을 사용해 선형 시스템 내에서 가중치가 부여된 방향성이 있는 비순환 그래프(DAG)를 도출하여 인과 관계를 파악
- DirectLiNGAM
-
결과 (Results)
- 영화 품질과 인기:
- 영화 평점은 주로 영화 품질에 의해 결정되지만, 영화 인기 역시 일정 부분 영향을 미침
- 이는 실제 사용자가 인기 있는 영화에 대해 높은 평점을 주는 경향과 일치함
- 인기도 편향 강화 피드백 루프:
- 인기 영화는 더 많은 노출과 시청을 유도하여, 이후 학습 데이터에 포함되면 추천 시스템이 이러한 영화를 더욱 많이 추천하게 되는 피드백 루프가 관찰됨
- 이러한 현상은 추천 시스템에서 인기도 편향(popularity bias)이 강화되는 원인을 설명해줌
- 영화 품질과 인기:
Limitations and Future Work
데이터 소스 제약
- 오프라인 데이터셋 사용으로 인한 상세 설명 부족 문제
- 온라인 데이터 수집의 어려움
제한된 행동 공간
- 소셜 네트워크, 광고, 입소문 등 미포함
- 실제 사용자 의사결정 과정 반영 미흡
- 행동 요소 확장의 필요성
LLM 환각 문제
- 부정확한 사용자 행동 시뮬레이션
- 존재하지 않는 아이템 생성 및 부적절한 평점 부여
- 시뮬레이션 결과 신뢰성 저하
- 추천 시나리오에 특화된 LLM 파인튜닝 필요성
Thoughts
- 강화학습 기반 추천시스템의 한계 중 하나인 추천 환경 설정 문제를 다양한 상황을 설계하여 실제 서비스 환경과 유사한 데이터를 생성함
- 에이전트 기반 강화학습 모델이 실제 사용자 행동을 모사함으로써, 해당 모델이 다시 주목받을 가능성이 있음
- 인과 추론 관점에서 단순 동조 및 관심사 외에도, 활동성, 다양성, 퍼널, 피로도 등 다양한 요소를 통합함
- 에이전트가 생성한 피로도는 실제 사람과 다를 수 있으나, 전반적으로 납득할 만한 수준으로 모사됨
- 코드가 공개되어 있어 분석 및 학습에 많은 도움이 될 것으로 보임
- 이 에이전트를 기반으로 인과 추론 모듈을 추가하여 다양한 실험을 진행할 수 있음
Leave a Comment:
로그인 후 댓글을 작성할 수 있습니다.
Comments:
No comments yet. Be the first to comment!