Google Agent white paper 리뷰
- 화질 안좋지만 두 페이지로 볼 수 있는 버전 : https://archive.org/details/google-ai-agents-whitepaper/page/6/mode/2up
- 화질 좋은 pdf 버전 : https://drive.google.com/file/d/1oEjiRCTbd54aSdB_eEe3UShxLBWK9xkt/view
Reasoning, Logic, 외부 정보로의 접근. 이 세 가지가 결합하여 생성형 AI 모델과 연결되면 Agent의 기초 개념이 된다.
- Reasoning : 추론. "무엇이 필요한지, 어떤 목표를 달성해야 하는지"를 생각
- Logic : 그 목표를 어떻게 달성할지, 어떤 순서와 규칙으로 행동할지"를 설계하고 실행
사람은 최종 결론에 이르기 전에 사전 지식을 보충하기 위해 책, 검색, 계산기 등을 사용한다. 생성형 AI 모델 역시 tool을 사용하도록 학습될 수 있다. 또, 실시간 정보에 접근하여 현실적인 액션을 제안할 수 있다. 예를 들어, 데이터베이스에서 구매 히스토리같은 정보를 추출하여 고객에게 상품을 추천할 수도 있다. 데이터베이스 tool을 사용하면 되니까. 또 다른 예로, 나 대신 이메일에 답장하도록 하려면 API를 사용하게 할 수도 있다. 이렇게 외부 툴(external tool)에 접근하려면 모델은 스스로 무엇을 할 지 계획하고 수행(execute)할 수 있어야한다.
이렇게 추론(reasoning), 논리(logic), 외부 정보 접근(access to external information)이 결합되어 생성형 AI 모델과 연결된다면, 당신은 이제 Agent의 컨셉을 떠올릴 준비가 되었다!
Agent란 무엇인가?
정보를 관찰한 후 자신이 사용 가능한 tool을 이용해 행동(act)함으로써 목표를 달성하는 애플리케이션이라고 정의할 수 있다. Agent는 인간이 개입하지 않아도 목표 달성을 위해 자율적으로 행동할 수 있어야 한다. 즉, 인간이 지시사항을 구구절절 입력하지 않은 상황에서도, 다음에 어떻게 해야하는지 스스로 추론(reason)할 수 있어야 한다.
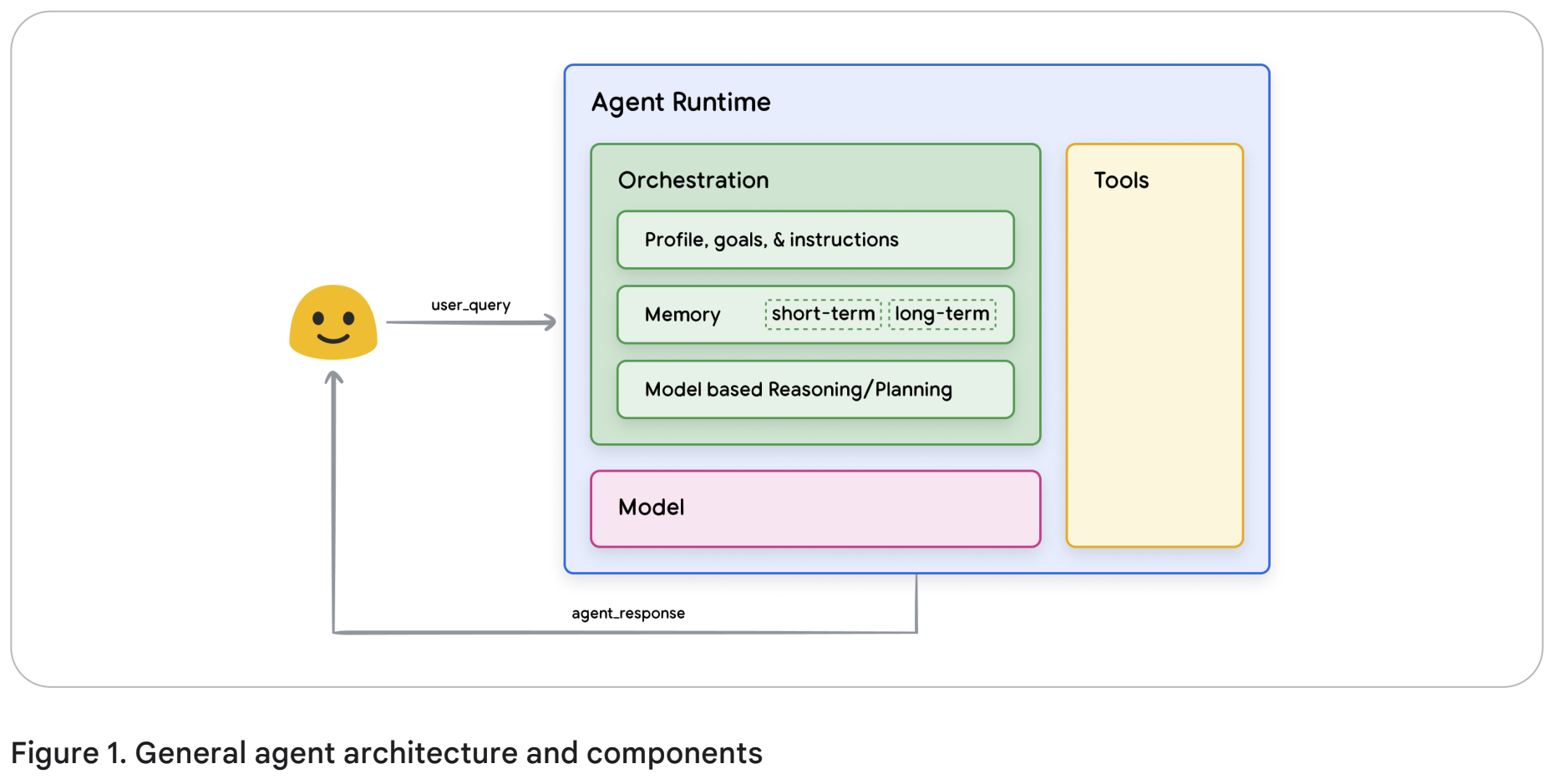
세 가지 필수적인 구성 요소가 있다.
-
Model
여기서 모델은 다들 아는 바와 같이 언어 모델을 의미한다. 모델은 의사결정자 역할을 한다. 작은 모델, 큰 모델 등 여러 모델을 사용할 수 있다. 또한 ReAct, Chain-of-Thought, Tree-of-Thoughts 등의 추론(reason)/논리(logic) 프레임워크에서 동작할 수 있으면 된다.
모델은 범용 모델, 멀티모달 모델, 특정 데이터에 파인튜닝된 모델 등이 사용될 수 있다. 목표를 잘 수행할 수 있는 모델을 선택해야한다. 가장 이상적인 것은 tool과 연관된 데이터로 학습된 모델을 쓰는 것이다.
하지만, 보통은 모델을 tool 선택이나 추론 방식에 맞춰 학습시키진 않는다. 대신, 예시들을 입력해줌으로써 fine-tuning의 효과를 볼 수 있다.
-
Tools
Foundation model 자체 성능은 놀라운 발전을 이뤄왔지만, 외부 세계와 상호작용할 수 없다는 점은 늘 한계점이었다. Tool이 이 간극을 매운다. 그럼으로써 Agent가 외부 데이터, 서비스들과 상호작용할 수 있게 한다.
Tool은 다양한 형태와 복잡도를 가질 수 있는데, 가장 기본적인건 GET, POST, PATCH, DELETE 같은 API 호출을 떠올릴 수 있다. 어느 tool은 데이터베이스에 고객 정보를 업데이트하는 API를 불러올 수 있다. 어느 tool은 날씨 데이터를 불러오게 할 수 있을거고, 이를 여행 추천에 활용할 수도 있을 것이다. RAG만으로 부족한 정보를 보충할 수도 있다.
-
Orchestration layer
위에서 말한 바에 따르면, Agent는 정보를 받아들이고, 추론(reasoning)을 하고, 그 추론을 다음 행동(action) 또는 의사결정에 사용한다. 이건 순환 과정이 된다. Orchestration layer는 이 순환 과정을 관장한다. 일반적으로 이 루프(loop)는 목표를 달성했거나 멈추도록 설정한 시점에 도달할 때까지 반복된다.
Orchestration layer의 복잡도는 수행하는 작업에 따라 크게 달라질 수 있을 것이다. 간단한 것은 정해진 규칙에 따라 숫자 계산만 할 수도 있고, 복잡한 것은 연쇄적인 로직과 머신러닝 알고리즘, 또는 다른 확률적 추론까지 결합할 수도 있을 것이다.
Agents vs Models
| Models | Agents |
|---|---|
| 학습된 데이터 속 지식에만 국한되어 답변함 | Tool을 통해 외부 시스템과 연결되어 지식을 확장시킬 수 있음 |
| 단일 입력과 출력. 단순 모델만 있다면, 채팅 기록같은 문맥을 관리하지 않음. | 세션 히스토리(채팅 기록)을 관리하여 멀티턴 상호작용이 가능하다. |
| 내장된 tool이 없음. | Tool이 에이전트 아키텍쳐 안에 내장되어 있음. |
| 내장된 로직 계층(logic layer)이 구현되어 있지 않음. |
단순한 질문 형태의 프롬프트를 입력하거나, CoT, ReAct 같은 추론 프레임워크를 활용하여 복잡한 프롬프트를 구성함으로써 모델의 예측을 유도할 수 있다.
즉, 모델 자체가 논리적 사고 과정을 내장하고 있는 게 아니라, 사용자가 어떤 방식으로 프롬프트를 설계하느냐에 따라 모델의 추론 능력이 달라진다. | CoT(Chain-of-Thought), ReAct 같은 추론 프레임워크나, LangChain 같은 사전 구축된 에이전트 프레임워크를 활용하는 내장형 인지 아키텍쳐(native cognitive architecture) |
인지 아키텍쳐(Cognitive architectures): 에이전트는 어떻게 동작하는가?
한 셰프가 분주한 주방에 있다고 상상해보자.
그들의 목표는 고객에게 맛있는 음식을 대접하는 것인데, 이는 ‘계획(planning) → 수행(execution) → 조정(adjustment)’의 순환이라고 할 수 있다.
- (Gathering information) 셰프는 정보를 수집한다. 예를 들어 고객의 주문 내용을 확인하고, 창고와 냉장고에 어떤 재료가 있는지 파악한다.
- (Reasoning) 그들이 수집한 정보(주문 내용, 재료를 사용 가능한지 등)를 바탕으로, 어떤 음식을 만들 수 있는지 내부적으로 추론(internal reasoning)을 한다.
- (Action) 재료를 썰고, 향신료를 갈고, 고기를 굽는 등 음식을 만들기 위해 행동한다(take action).
각 단계에서 셰프는 필요에 따라 조정(adjustment)을 한다. 갑자기 냉장고에 있는 재료가 소진될 수도 있고, 손님이 ‘덜 맵게 해주세요’라고 할 수도 있지 않나. 셰프는 다음에 할 행동을 계획하기 위하여 지금 시점 이전의 결과들을 참고한다. 이처럼 정보 수집(information intake) → 계획(planning) → 실행(executing) → 조정(adjusting)의 순환 과정이 바로 셰프가 목표를 달성하기 위해 사용하는 자신만의 인지 아키텍쳐(Cognitive architecture)이다.
마치 셰프와 같이, 에이전트도 이러한 인지 아키텍쳐를 사용할 수 있고 반복적으로 정보를 처리하고, 의사 결정을 하며, 다음 행동을 조정해나감으로써 최종 목표에 도달한다. 여기서 다음 행동을 조정(adjusting)해나간다는 것은 셰프가 “소금을 더 추가하고”, “불을 약하게 조정하는” 것과 같을 것이다!
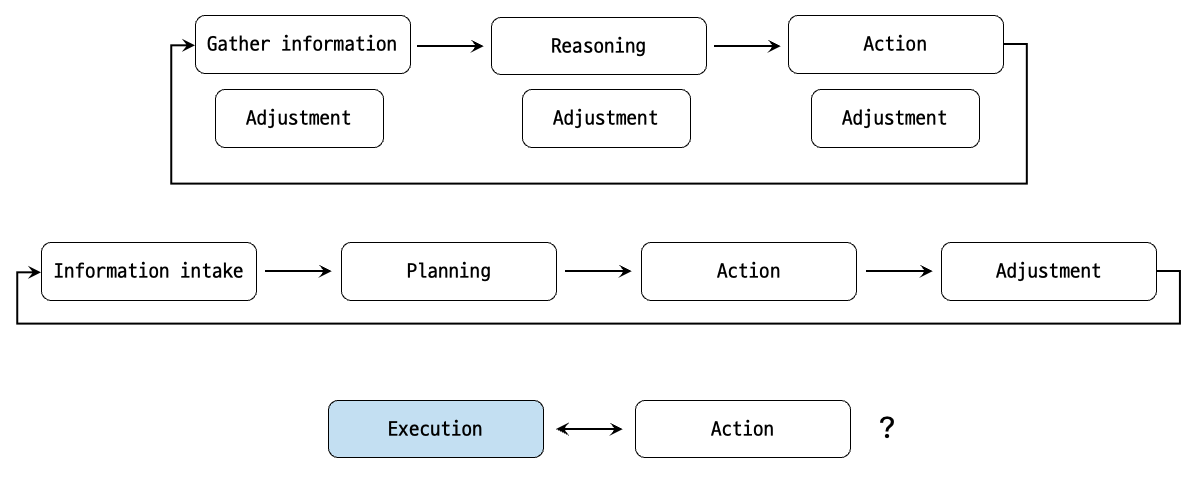
나는 약간 혼란스럽다. 여러 단어들이 혼재돼있다. 그냥 내가 만들고자 하는 앱의 필요에 따라 짜면 되는거겠지?
인지 아키텍쳐의 핵심은 orchestration layer에 있다. Orchestration layer는 에이전트의 두뇌처럼 지속적으로 메모리(memory), 현재 상태(state), 추론(reasoning), 계획(planning)을 관리한다. Orchestration layer는 빠르게 발전하고 있는 프롬프트 엔지니어링 분야, 또는 그에 관련된 프레임워크를 활용하여 추론과 계획을 이끌어낸다. 그렇게 에이전트는 주변 시스템들과 효과적으로 의사소통하면서 태스크를 완수할 수 있다.
프롬프트 엔지니어링 프레임워크와 언어 모델의 ‘task planning’ 분야는 빠르게 발전하고 있으며 다양한 접근법들이 존재한다. 이 글이 작성된 시점에서 가장 널리 사용되는 프레임워크와 추론 기법은 다음과 같다.
- ReAct : 모델이 유저 쿼리에 대해서 추론(reason)하고 행동(action)할 수 있도록, 사고 과정을 설계해주며, in-context example이 있든 없든 활용할 수 있다.
- In-context example란 모델에 입력으로 같이 주는 예시로, “Q: 2+2는? A: 4” 같은 예시이다.
- ReAct 예시(Thought → Action → Observation → Answer)
- Thought (생각): “내가 직접 계산할 수는 없고, 최신 정보를 얻으려면 검색 도구를 써야겠다.”
- Action (행동): “위키피디아 검색: 에펠탑 높이”
- Observation (관찰): “검색 결과: 에펠탑 높이는 330m”
- Final Answer (최종 답변): “에펠탑의 높이는 약 330미터입니다.”
-
Chain-of-Thought(CoT) : 중간 스텝을 통해 추론 능력을 가능하게 하는 프롬프트 엔지니어링 프레임워크다. CoT의 하위 기법이 여럿 존재하며 Self-consistency, Active-prompt, Multimodal CoT 등이 있다.
- 모델이 답만 뱉지 않고, 추론 과정을 단계별로 적어가며 해결하도록 하는 기법
- 그냥 답: “17 × 24 = 408”(틀릴 수 있음)
- CoT 방식:
- “17 × 20 = 340”
- “17 × 4 = 68”
- “340 + 68 = 408”
- “따라서 답은 408”
- Self-consistency: 여러 CoT 답변을 생성해 가장 일관된 결론 선택
- Active-prompt: 필요할 때만 추론 단계를 쓰도록 조절
- Multimodal CoT: 텍스트 외에 이미지·표 같은 입력도 중간 추론에 활용
변형 기법들:
- Self-consistency: 여러 CoT 답변을 생성해 가장 일관된 결론 선택
- Active-prompt: 필요할 때만 추론 단계를 쓰도록 조절
- Multimodal CoT: 텍스트 외에 이미지·표 같은 입력도 중간 추론에 활용
- Tree-of-Thoughts(ToT) : 이는 CoT를 일반화한 방식으로, 모델이 다양한 사고 경로(thought chains)를 중간 단계로써 탐색하도록 하는 방법이다. 탐색(exploration)이나 *전략적 선행 계획(strategic lookahead) 태스크에 적합한 프롬프트 엔지니어링 프레임워크이다.
- 단일 추론 경로(체인)만 따르다가 잘못된 길에 빠질 위험을 줄일 수 있고, 여러 가지 추론 경로(branch) 를 탐색, 평가함으로써 복잡한 문제나 시뮬레이션이 필요한 과제를 푸는 데 강하다.
- *전략적 선행 계획(strategic lookahead) 과제란, 쉽게 말해 앞으로 벌어질 결과까지 내다보며 미리 계획을 세워야 하는 과제. 체스에서 다음 수를 두기 전에 몇 수 앞까지 시뮬레이션하는 것, 경영 의사결정에서 여러 시나리오를 시뮬레이션하는 것.
- 여러 가지 추론 경로를 동시에 탐색·비교하면서, 미래 상황까지 내다봐야 하는 과제를 더 잘 푼다.
에이전트는 다음에 수행할 액션을 고르기 위해 위 같은 추론 방법들을 사용할 수 있다. 예를 들어 ReAct를 쓰는 에이전트가 있다고 해보자. 아마 다음과 같은 순서로 진행될 것이다.
- 유저가 쿼리를 입력
- 에이전트는 ReAct 시퀀스를 시작
- 에이전트는 모델에 프롬프트를 제공하고, 모델은 다음 ReAct 단계 중 하나와 해당 단계의 결과를 생성하도록 요청
- Question : 유저의 질문
- Thought : 모델이 “다음에 무엇을 해야 할지”에 대한 내부적 사고 과정
- Action : 모델이 선택한 다음 행동
- 여기서 도구 선택(tool choice) 가능
- 예를 들어, Action은 [Flights, Search, Code, None] 중 하나일 수 있는데, 앞의 3개는 모델이 선택할 수 있는 알려진 도구를 의미하고, 마지막 None은 “도구를 사용하지 않음”을 의미함
- Action input : (필요하다면)모델이 도구에 전달할 입력값 결정
- Observation : Action과 Action input을 실행한 뒤 얻은 결과
- 이 Thought → Action → Action input → Observation 사이클은 필요할 경우 여러 번 반복될 수 있음.
- Final answer : 모델이 최종적으로 사용자 쿼리에 제공하는 답변
- ReAct 루프가 종료되고 최종 답변을 유저에게 전달
Figure 2. Example agent wigh ReAct reasoning in the orchestration layer
Figure 2를 보자. Model, tools, agent 설정이 서로 협력하여 유저에게 현실적이고 정확한 응답을 제공한다. 모델이 사전 지식만으로 대답했다면 할루시네이션에 의해 추정에 가까운 대답을 했겠지만, 위 경우는 Flights라는 tool을 사용함으로써 실시간 외부 정보를 검색했다. 이 추가 정보가 모델에 전달되어, 실제로 사실인 데이터에 기반해 의사결정을 내릴 수 있다.
결국, 에이전트의 응답 품질은 모델의 추론, 행동 능력에 달려있다. 즉, 올바른 tool을 선택하고, 그 tool이 잘 정의되어 있는지 말이다.
Tools : 바깥 세계로 가는 열쇠
언어 모델은 실제 세상을 직접 관찰하거나 영향을 미칠 수 있는 능력은 갖추고 있지 않다. 그렇다면, 우리의 모델이 외부 시스템과 실시간으로, 그리고 상황(context)을 고려한 상호작용을 할 수 있도록 어떻게 강화할 수 있을까? 이를 가능하게 하는 중요한 방법으로 함수(Functions), 확장(Extensions), 데이터 저장소(Data Stores), 플러그인(Plugins) 등이 있다.
Tool은 모델과 외부 세계를 연결해 정확하고 신뢰성 있는 답변을 할 수 있도록 한다. 예를 들어, tool은 에이전트가 스마트홈 세팅을 조정하도록 할 수 있고, 캘린더를 업데이트하도록 할 수 있고, 데이터베이스로부터 유저의 정보를 가져오게 할 수 있고, 특정 지침에 따라 이메일을 보내게 할 수도 있다.
Extensions(=API?)
Extension을 이해하기 가장 쉬운 방법은 Extension을 API와 에이전트를 연결하는 표준화된 다리(bridge)라고 생각하는 것이다. 비행기표를 예약을 도와주는 목표를 가진 에이전트를 만들었다고 해보자. 당신은 Google Flights API를 사용하면 된다는걸 알지만, 에이전트에게 이 API 엔드포인트를 언제, 어떻게 호출해야 하는지 어떻게 가르쳐야할까?

한 가지 방법은, 유저 쿼리를 받아 관련 정보에 대해 그 쿼리를 파싱하는 커스터마이징된 코드를 짜서 API를 호출하는 것이다. 예를 들어, 유저가 “오스틴에서 취리히로 가는 항공편을 예약하고 싶다”고 입력했다고 하자. 위 방법대로라면 유저의 코드는 질문으로부터 “오스틴”과 “취리히”를 추출해야한다. 하지만, 출발지 없이 “취리히로 가는 항공편 예약하고싶어”라고 한다면? 필수 정보가 없으므로 API 호출을 할 수 없고, 이런 케이스만을 처리하기 위한 코드가 필요해진다. 이 방법은 scalable하지 못하며 커스터마이징된 코드를 벗어나는 케이스에 대해서는 실패하고 만다.
Extension을 사용하면 안정적이고 견고해질 수 있다. Extension은 에이전트와 API 사이의 갭을 다음과 같은 방식으로 연결(bridge)한다:
- 예제를 보여주어 Agent가 어떤 API를 호출해야 하는지 알려준다.
- 그 API 엔드포인트를 성공적으로 호출하기 위해 어떤 인자가 필요한지 알려준다.
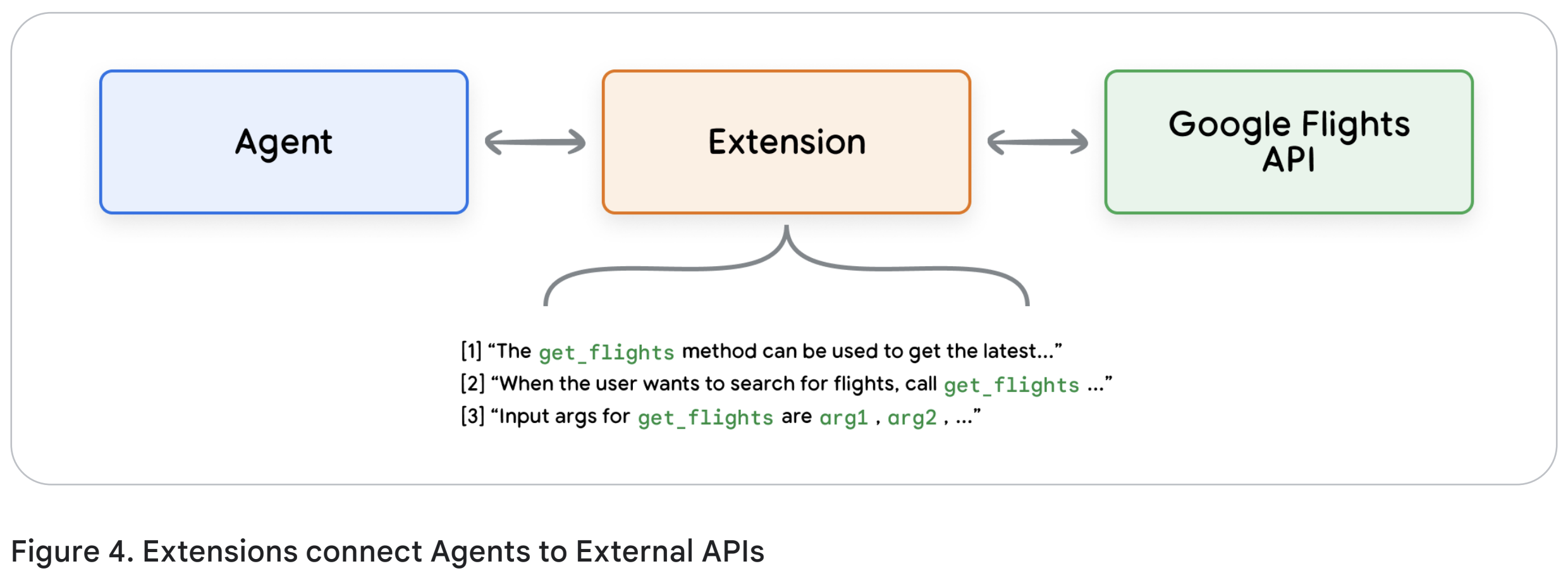
Extension은 에이전트와 별개로 독립적으로 만들어질 순 있지만, 에이전트 설정(configuration)에 포함시켜야 한다. 셰프가 새로운 조리 도구를 따로 준비해도 되지만, 실제 주방에서 자주 쓰는 도구 선반에 포함시켜야 요리 중에 바로 쓸 수 있는 것처럼 말이다. 에이전트는 런타임 도중에 모델과 예시를 사용해서 어떤 Extension이 적합한지, 아니면 사용하지 않을지 결정한다. 이것이 Extension의 핵심적인 강점인데, 바로 내장된 예시(built-in example) 기능이다. 이미 만들어져 있는, 에이전트가 바로 쓸 수 있는 도구 세트라고 볼 수 있다.
이를 통해 에이전트는 가장 적합한 Extention을 동적으로(dynamic) 선택할 수 있다. 셰프가 요리 중에 “이번 요리에는 이 도구가 가장 적합하겠군” 하고 즉시 선택하는 상황처럼.

현실의 예시를 볼까? 소프트웨어 개발자가 유저의 문제를 풀기 위해 어떤 API 엔드포인트를 사용할지 결정할 때와 똑같은 것이다. 유저가 항공편 예약을 원한다면 Google Flights API를 사용해야 할 것 이다. 유저가 현재 위치 기준으로 가장 가까운 카페를 알고 싶어한다면, 개발자는 Google Maps API를 사용해야 할 것이다. 똑같이, 에이전트와 모델은 이미 알려진 Extension 집합을 활용하여 유저의 질문에 가장 적합한 Extension이 뭔지 결정한다.
Functions
개발자는 함수를 만들며 언제 function_a를 호출할 지, function_b를 호출할지에 대한 로직과 입력과 아웃풋을 정의한다.
에이전트 세계에서는, 개발자 역할을 모델이 수행한다고 볼 수 있다. 모델은 미리 정의된 함수들을 가지고 언제, 어떤 인자를 사용할지를 명세(specification)에 따라 결정할 수 있다. Function과 Extension의 주요 차이점은 다음과 같다 :
- 모델은 함수와 그 인자를 출력한다. 실시간 API 호출은 하지 않는다.
- Function은 클라이언트 측에서 실행되지만, Extension은 에이전트 측에서 실행된다.
항공편 예약 예시를 들어 간단한 함수의 설정을 보자면 아래 Figure 7과 같다.
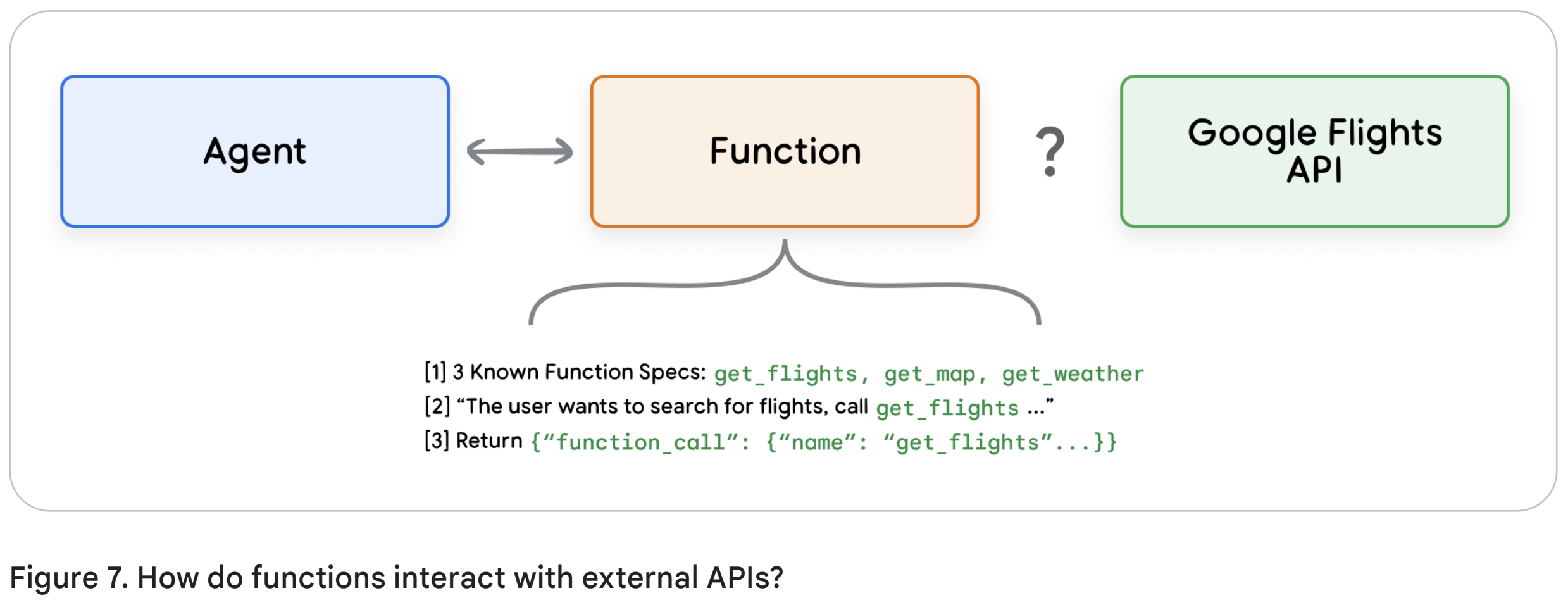
Extension과의 핵심점인 차이점은, 함수(Function)도 에이전트(agent)도 Google Flights API와 직접 상호작용하지 않는다는 점이다. 그렇다면 API 호출은 실제로 어떻게 일어나는 걸까?
함수들을 사용하면, 실제 API 엔드포인트를 호출하는 로직과 실행이 에이전트에서 벗어나 클라이언트 측 애플리케이션에 다시 위임된다. 이는 아래 Figure 8과 Figure 9에서 볼 수 있다.
이 방식은 개발자에게 애플리케이션 내 데이터 흐름을 보다 세밀하게 제어할 수 있는 권한을 제공한다. 개발자가 Extension 대신 Function을 선택하는 데에는 여러 가지 이유가 있으며, 대표적인 사례는 다음과 같다:
- API 호출이 에이전트 아키텍처의 직접적인 흐름이 아닌, 애플리케이션 스택의 다른 레이어(예: 미들웨어 시스템, 프론트엔드 프레임워크 등)에서 이루어져야 하는 경우
- 보안 또는 인증 제약으로 인해 에이전트가 API를 직접 호출할 수 없는 경우 (ex. API가 인터넷에 노출되지 않았거나 에이전트 인프라에서 접근 불가능한 경우)
- 에이전트의 실시간 API 호출을 방해하는 타이밍 또는 작업 순서의 제약이 있는 경우 (예: 배치 처리, human-in-the-loop 리뷰 등)
- 에이전트가 처리할 수 없는 추가적인 데이터 변환 로직을 API 응답에 적용해야 하는 경우. 예를 들어, API 엔드포인트에서 반환되는 결과의 수를 제한할 수 있는 필터링 기능을 제공하지 않는다고 가정해보자. 이럴 때 클라이언트 측에서 함수를 사용하면 개발자가 이러한 변환 작업을 직접 적용할 수 있는 추가적인 기회를 얻게 된다.(무슨말인가?)
- 검색 API가 필터링 기능을 지원하지 않는 경우
- API: “상품 검색 API”
- 응답: 10,000개의 상품 리스트 반환 (필터 옵션 없음)
- 문제: 에이전트는 이 결과를 그대로 받으면 너무 방대하고 쓸모 없음
- 해결: 클라이언트 Function에서 아래와 같은 조건으로 필터링해서 정제된 결과만 모델/사용자에게 전달
- 가격 < 50,000원
- 카테고리 = “스포츠/레저”
- 평점 ≥ 4.5
- API가 외부 서비스(3rd-party API) 이거나, 내부 API지만 구조상 쉽게 변경할 수 없는 경우가 많음. API는 무조건 10,000개 상품을 던져줌 → 이걸 클라이언트 애플리케이션 측 Function이 받아서 필터링한다.
- 에이전트 → “상품 검색 API를 호출해봐”
- 클라이언트 측 Function → API 호출 결과(10,000개) 받음
- 클라이언트 측 Function → 거기서 가격/카테고리/평점 조건을 직접 적용 → 결과를 줄여서 모델/사용자에게 전달
- 에이전트가 직접 필터링 로직을 다루는 게 아니라, 클라이언트 Function에서 응답을 필터링/변환/가공/정제하는 권한을 갖는 것이 Function Calling의 장점
- API가 불완전하거나 제약이 있을 때, 클라이언트에서 보완적으로 처리할 수 있다.
- 검색 API가 필터링 기능을 지원하지 않는 경우
- 개발자가 API 엔드포인트용 별도의 인프라를 배포하지 않고도 에이전트 개발을 반복(iterate)하고 싶을 경우. 함수 호출(Function Calling)은 API를 스텁(stub) 처리하는 것처럼 활용될 수 있음. (Stub = 임시 대체물, 가짜 구현). 즉, 인프라 없어도, 실제 API를 배포하지 않고도, 함수 호출을 이용해 마치 API가 있는 것처럼 개발과 테스트를 진행할 수 있음.
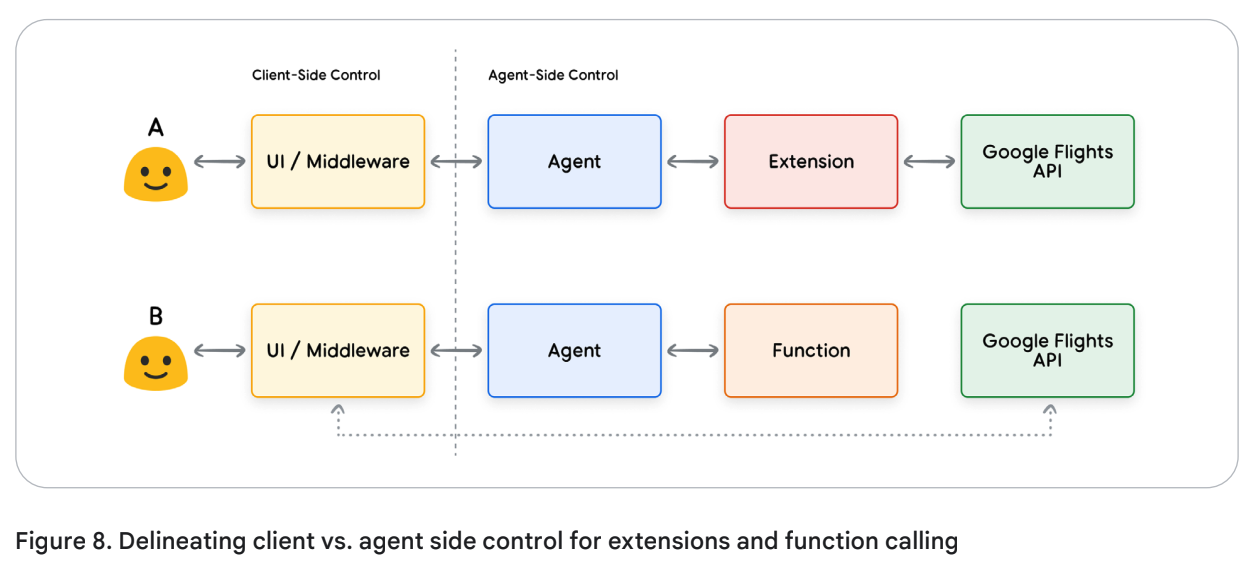
두 방식(Extensions, Functions)에서 제어 권한이 어디(에이전트 vs 클라이언트)에 있는지를 구분
Figure 8에서 볼 수 있듯이, 두 가지 접근 방식 간 내부 아키텍처의 차이는 미묘하지만, 추가적인 제어 권한과 외부 인프라에 대한 의존성을 분리할 수 있다는 점 때문에 Function Calling은 개발자에게 매력적인 선택지가 된다.
Use cases
모델은 복잡한 클라이언트 측 실행 플로우를 처리하기 위해 함수를 호출하는 데 활용될 수 있다. 이때 에이전트 개발자는, Extension처럼 언어 모델이 직접 API를 실행하는걸 원하지 않을 수도 있다. 예를 들어, 여행 컨시어지 역할을 하는 에이전트가 여행을 예약하고자 하는 사용자와 상호작용한다고 해보자. 여기서의 목적은 에이전트가 우리의 미들웨어 어플리케이션 안에서 사용할 수 있는 도시 리스트를 생성하도록 시키는 것이다. 이렇게 하면 애플리케이션이 해당 도시들의 이미지나 데이터를 내려받아 사용자의 여행 계획을 돕게 할 수 있다. 유저가 이렇게 입력했다고 해보자:
“가족들과 스키 여행을 가고 싶은데 어디로 가야할 지 모르겠어”
일반적인 프롬프트로는 다음과 같은 대답을 할 것이다:
“좋아요. 가족과 함께 가는 스키 여행지로 고려할만한 도시는 다음과 같아요:
- Crested Butte, Colorado, USA
- Whistler, BC, Canada
- Zermatt, Switzerland”
위 대답은 우리가 필요한 도시명 데이터를 포함하고 있는 반면, 형식은 파싱하기에 적절치 못하다. Function Calling을 사용하면 다른 시스템이 파싱하기 좋도록 Json같은 구조화된 아웃풋으로 대답하도록 지시할 수 있다.
function_call { name: "display_cities" args: { "cities": ["Crested Butte", "Whistler", "Zermatt"], "preferences": "skiing" } }
이 Json payload는 모델에 의해 생성되어 우리가 원하는 작업을 수행하기 위하여 클라이언트 측의 서버로 전송된다. 이런 케이스에서는 Google Places API를 호출해서 모델이 생성한 도시들의 이미지를 조회하고, 그 결과를 풍부한 대답으로 만들어 유저에게 보여주게 된다. Figure 9의 sequence diagram을 보면 이 작업을 디테일하게 보여주는 것을 확인할 수 있다.
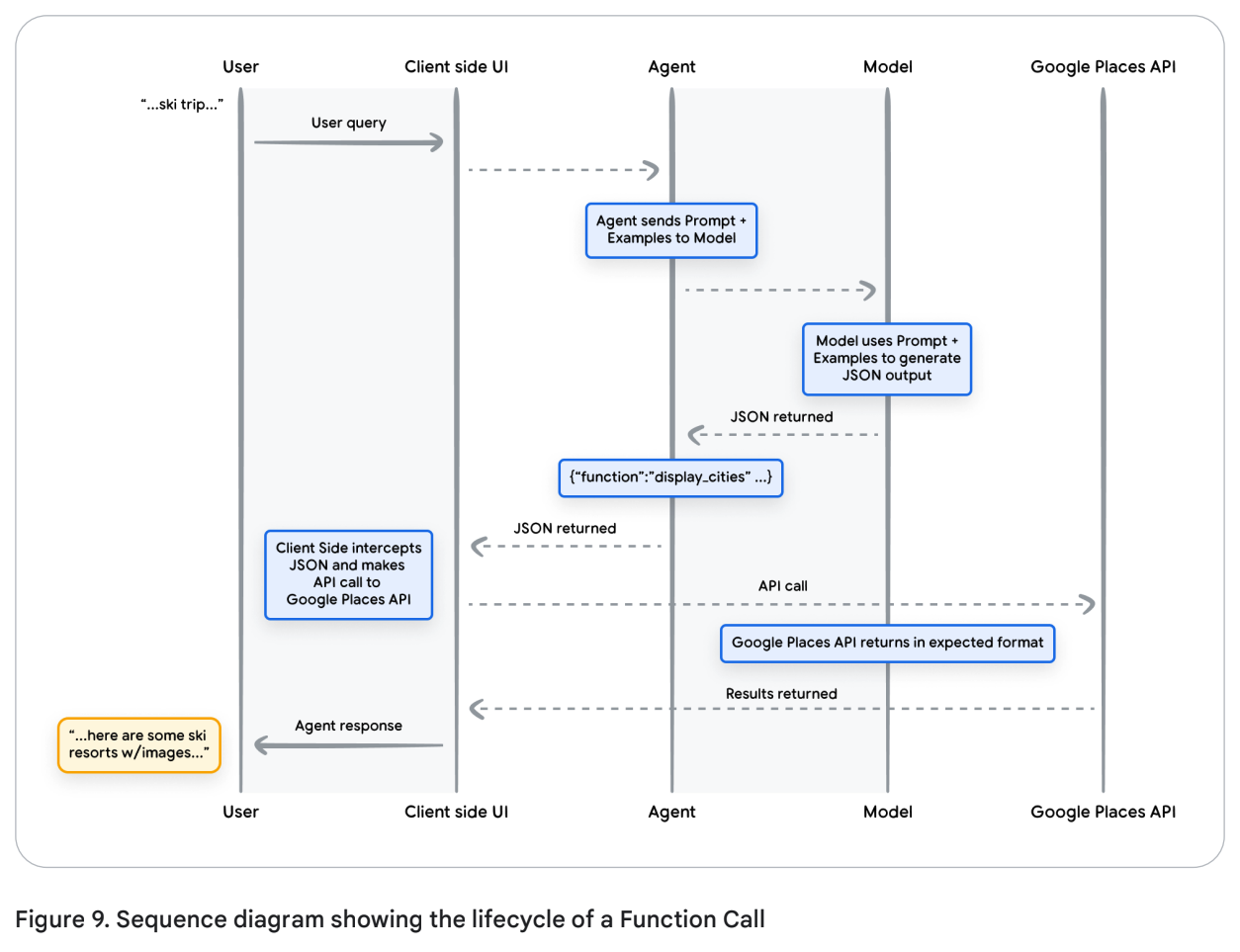
Figure 9를 보면, 모델이 “빈칸 채우기” 역할을 수행하여 이용되고 있다. 즉, 클라이언트 측 UI가 Google Places API를 호출하는 데 필요한 파라미터가 있을 것이고, 모델이 이 파라미터들을 제공해준다. 클라이언트 측 UI는 모델이 반환한 Function(여기서는 ”display_cities”)에 포함된 파라미터를 사용해 실제로 API를 호출한다. 이는 Function Calling의 하나의 활용 사례일 뿐이며, 이 외에도 다양한 시나리오들이 존재한다.
- 코드에서 사용할 함수를 언어 모델이 제안해주길 원하지만, 코드 안에 인증 정보(credentials) 를 포함하고 싶지 않은 경우. Function Calling은 에이전트가 함수를 실제로 실행하지 않기 때문에, 인증 정보를 코드에 넣을 필요가 없다.
- 몇 초 이상 소요될 수 있는 비동기 작업(asynchronous operations)을 실행하는 경우. Function Calling은 비동기 방식으로 동작하기 때문에 이런 시나리오에 적합하다.
- 함수 호출이 실행되는 device와 파라미터를 생성하는 device를 다르게 하고 싶은 경우.
결국 Function을 사용하는 의미는, 개발자가 API 호출 제어권에 더해 어플리케이션 전체 데이터의 흐름에 대한 제어권 더 많이 갖게 된다는 것이다. 보통 에이전트 방식에서는, 어떤 API를 호출할지·언제 호출할지를 에이전트가 내부적으로 처리한다. Function Calling을 쓰면, 모델이 “이 함수를 써라”라는 제안만 하고, 실제로 API를 실행하는 건 개발자(클라이언트 코드)가 맡게 된다. 그래서 API 호출의 시점, 순서, 방식을 개발자가 원하는 대로 제어할 수 있다.
Figure 9에서의 예시에서는 개발자가 API 응답을 에이전트에게 돌려주지 않는다. 에이전트가 딱히 할 일이 없다고 판단하였기 때문이고, 바로 Client side UI로 반환했다. 그러나 애플리케이션의 아키텍처에 따라서는 외부 API 응답을 에이전트에 반환하여 추론, 로직, 행동 선택을 시키는 것이 더 합리적일 수도 있다. 이렇게, 단순히 API 결과를 그대로 에이전트에 넘길지, 일부만 넘길지, 아니면 에이전트에는 주지 않고 클라이언트 UI에만 쓰일지를 개발자가 결정할 수 있다. 즉, Function을 쓰면 에이전트는 두뇌 역할(무슨 함수 써야 하는지 판단)만 하고, 실행과 데이터 흐름의 설계는 개발자가 원하는 대로 짤 수 있다. 애플리케이션에 따라 개발자가 적합한 방식을 선택하면 된다.
Data stores
언어 모델을 책들이 모인 도서관이라고 생각하고, 학습데이터로 학습도 완료되었다고 상상해보자. 새로운 출판 버전을 계속해서 추가하는 도서관과는 다르게, 모델은 최초에 학습된 지식에만 그쳐 있는 상황을 생각해보자. 하지만 실제로 현실의 지식은 계속 진화하고 있다. Data Store는 최신 정보에 접근할 수 있도록 함으로써 이러한 한계를 해결한다. 그리고 모델의 응답을 현실 기반의 팩트에 기반하도록 만들어준다.
한 개발자가 엑셀이나 Pdf같은 형태의 데이터를 모델에 추가적으로 제공해야하는 상황을 상상해보자.
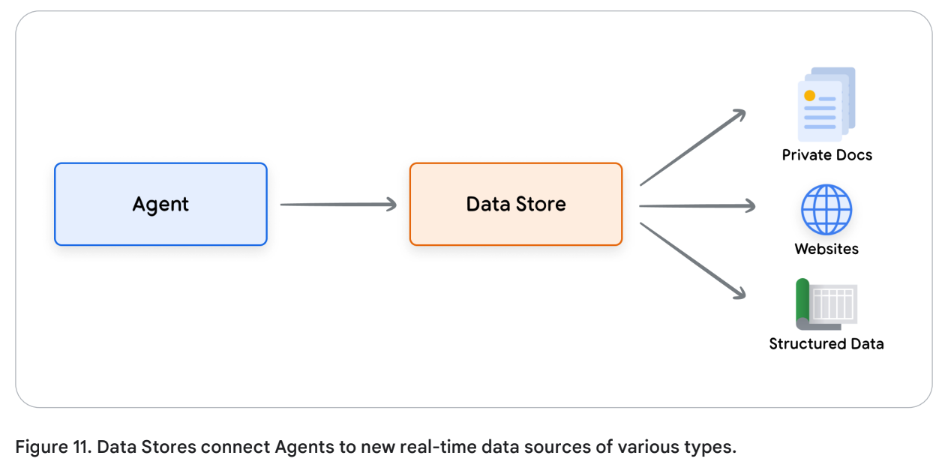
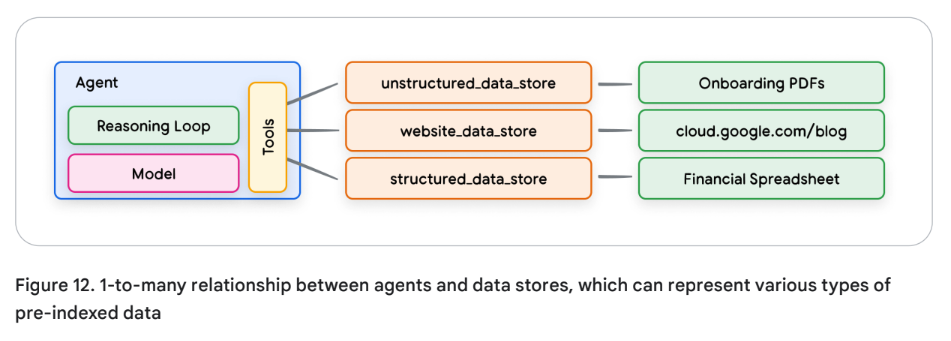
Data Store를 사용하면 개발자는 추가할 데이터를 그 포맷 그대로 에이전트에게 제공할 수 있다. 데이터의 형태를 변환 시키기 위해 시간 낭비를 안해도 되고, 모델 재학습이나 파인튜닝 할 필요도 없어진다. Data store는 입력되는 document를 벡터 데이터베이스 임베딩으로 변환하고, 에이전트는 다음 행동이나 유저 응답에 필요한 보충자료를 벡터 데이터베이스 임베딩으로부터 추출할 수 있다.
생성형 AI Agent 관점에서 Data store란, 일반적으로 런타임 동안에 에이전트가 접근할 수 있도록 구현된 벡터 데이터베이스 형태를 말한다.
RAG가 가장 널리 사용되는 사례 중 하나이다. RAG를 사용하면 웹사이트 컨텐츠, PDF, 워드 문서, CSV, 스프레드시트 같은 구조적 데이터, HTML, PDF, TXT 등 비구조적 데이터 등에 접근할 수 있다.
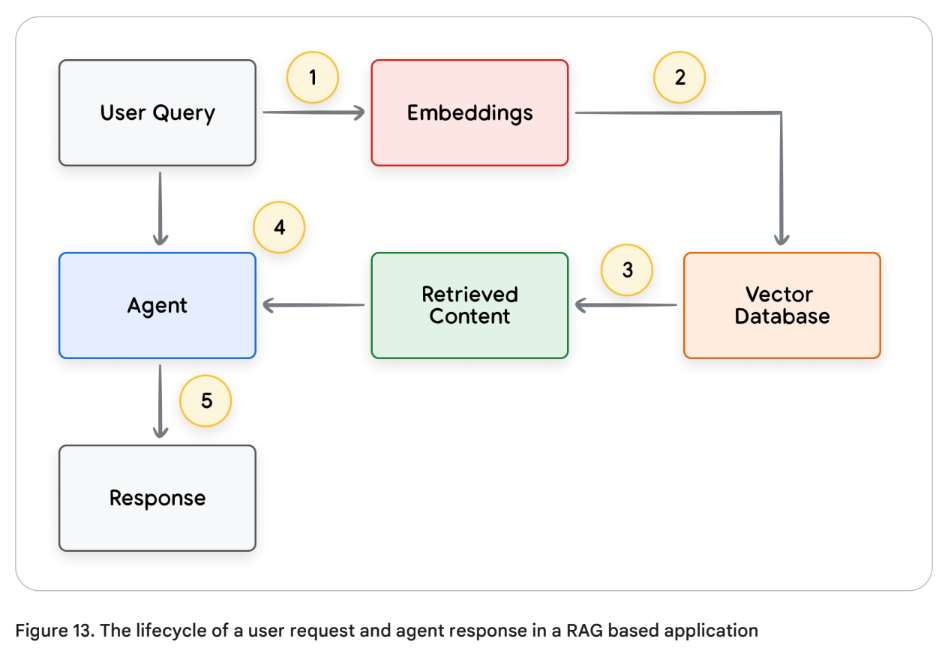
Data store를 사용한 일반적인 요청–응답 루프 과정은 다음과 같다(Figure 13)
- 사용자의 쿼리를 임베딩 모델에 보내, 쿼리 임베딩을 생성
- 생성된 쿼리 임베딩을 벡터 데이터베이스의 콘텐츠와 비교(match) (예: SCaNN 같은 매칭 알고리즘 사용)
- 매칭된 콘텐츠를 벡터 데이터베이스에서 텍스트 형식으로 가져.
- 에이전트는 사용자 쿼리와 함께 가져온 콘텐츠를 받아 응답이나 행동을 생성.
- 응답이 유저에게 보냄.
최종적으로, 애플리케이션은 에이전트가 사용자 쿼리를 벡터 검색으로 Data store와 연결하고, 필요한 원본 콘텐츠를 찾아 가져와, 이를 오케스트레이션 레이어와 모델에 전달해 후속 처리를 할 수 있게 해준다.
ReAct reasoning/planning를 통해 RAG를 수행하는 에이전트 샘플은 아래 Figure 14에서 확인할 수 있다.
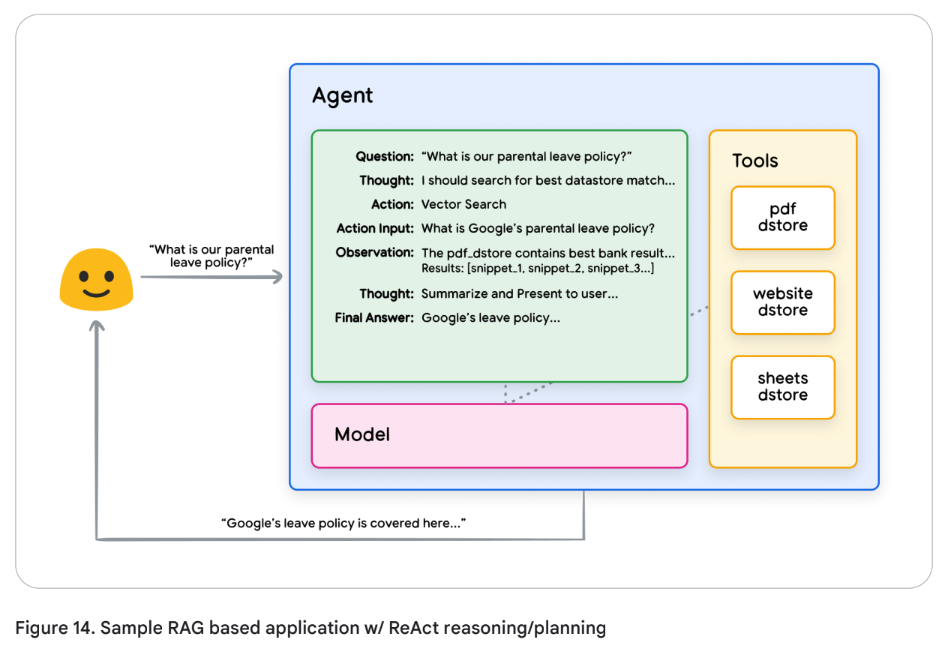
- Question: “우리 회사 육아휴직 제도가 어떻게 되어 있어?”
- Thought: 적절한 데이터 스토어를 찾아봐야겠다.
- Action: Vector Search
- Action Input: Google의 육아 휴직 제도는?
- Observation: pdf 데이터 스토어에서 가장 잘 매칭되는 결과를 찾음(bank는 오타고 rank인 것 같음). 결과: [snippet_1, snippet_2, snippet_3…]
- Thought: “이제 요약해서 사용자에게 보여주자…”
- Final Answer: “Google의 육아휴직 제도는 … 입니다.”
Tools Recap
에이전트가 런타임에 사용할 수 있는 도구 유형은 크게 Extensions, Function Calling, Data Stores로 나눌 수 있다.
각각 고유한 목적이 있으며, 개발자의 설계에 따라 독립적으로 또는 함께 사용할 수 있다.
Extensions
- 실행 주체: 에이전트 측 실행 (Agent-Side Execution)
- 주요 용도
- 에이전트가 직접 API 엔드포인트와 상호작용하도록 하고 싶을 때
- 네이티브로 제공되는 사전 구축된 Extension 활용 (예: Vertex Search, Code Interpreter 등)
- 멀티홉 플래닝 + API 호출이 필요한 경우
- ex. 이전 단계 API 호출 결과에 따라 다음 행동이 결정되는 시나리오. 에이전트가 한 번의 추론이나 한 번의 API 호출로 끝나지 않고, 여러 단계(= 여러 hop) 를 거쳐 최종 답을 얻는 방식일 때
- ex. 여행 계획 시나리오. 사용자가 질문: “가족 여행지 추천해줘. 눈 오는 도시에서, 5성급 호텔도 있으면 좋겠어.” 에이전트 단계별 동작: (첫 번째 API 호출) 날씨 API → 눈 오는 도시 목록 검색. (두 번째 API 호출) 호텔 예약 API → 그 도시들 중 5성급 호텔 여부 확인. (최종 결정) 두 결과를 종합해서 사용자에게 답변. 여기서 첫 번째 API 결과가 두 번째 API 입력을 결정한다. → 이것이 멀티홉 플래닝 + API 호출
- 쉽게 말하면, 에이전트가 단계별로 생각하고, 앞 단계 API 결과를 바탕으로 다음 단계 행동을 결정하는 방식
Function Calling
- 실행 주체: 클라이언트 측 실행 (Client-Side Execution)
- 주요 용도:
- 보안/인증 제약으로 인해 에이전트가 API를 직접 호출할 수 없을 때
- 실시간 호출이 어려운 경우 (배치 처리, human-in-the-loop 검토 등)
- 인터넷에 노출되지 않거나, Google 시스템에서 접근할 수 없는 API를 사용해야 할 때
Data Stores
- 실행 주체: 에이전트 측 실행 (Agent-Side Execution)
- 주요 용도:
- RAG (Retrieval Augmented Generation) 구현 시 활용
- 지원 데이터 타입:
- 웹사이트 콘텐츠 (사전 인덱싱된 도메인/URL)
- 구조화 데이터 (PDF, Word, CSV, 스프레드시트 등)
- 관계형/비관계형 데이터베이스
- 비구조화 데이터 (HTML, PDF, TXT 등)
정리
- Extensions → 에이전트가 직접 API를 실행/조율할 때 유용
- Functions → 실행은 클라이언트가 담당, 보안/타이밍 제약이 있는 API 처리에 적합
- Data Stores → 에이전트가 벡터 검색 기반으로 외부 지식에 접근해 RAG 구현
Engancing model performance with targeted learning
(모델 성능 향상: 타겟 학습을 통한 접근)
모델을 효과적으로 활용하는 데 있어, 특히 프로덕션 환경에서 대규모로 도구를 사용할 때 중요한 요소 중 하나는 모델이 올바른 도구를 선택할 수 있는 능력이다. 일반적인 학습도 모델이 잘 선택할 수 있도록 할 수 있지만, 현실적으로는 학습 데이터 이 외의 데이터도 필요하다. 이를 기본 요리 기술과 특정 요리 전문성 의 차이로 비유할 수 있다. 두 경우 모두 요리에 대한 기초 지식이 필요하지만, 후자는 더 세밀한(nuanced) 결과를 위해 targeted learning이 요구된다.
모델이 특정 지식에 접근할 수 있도록 하기 위해(도와주기 위해), 다음과 같은 접근법들이 존재한다:
- In-context learning : 추론 시점(inference time)에 프롬프트, tools, 몇 가지 예시(few-shot examples)를 모델에 제공하여 모델이 특정 작업에 필요한 도구를 즉석(on the fly)으로 학습하도록 돕는 방식. ReAct 프레임워크가 대표적이 예.
- Retrieval-based in-context learning : 외부 메모리에서 관련 정보, 도구, 예시를 검색해 모델 프롬프트에 동적으로 주입하는 방식. Vertex AI Extensions의 Example Store, 혹은 앞서 언급한 RAG 기반 아키텍처의 데이터 스토어가 대표적이 예.
- Fine-tuning based learning : 추론 전에, 특정 예시들로 구성된 더 큰 데이터셋을 사용해 모델을 사전 학습(fine-tune) 하는 방식. 모델은 이를 통해 사용자 쿼리를 받기 전부터 어떤 도구를 언제, 어떻게 써야 할지 더 잘 이해하게 됨.
각 방식에 대해 추가적인 인사이트를 얻기 위해 요리 예시를 다시 보자.
- In-context learning : 고객이 셰프에게 레시피(프롬프트), 몇 가지 핵심 재료(도구), 예시 요리(샘플)를 줬을 때, 셰프는 일반 요리 지식에 더해 이 제한된 정보를 바탕으로 즉석에서 요리를 만들어내야 함.
- Retrieval-based in-context learning : 셰프가 잘 갖춰진 식재료 창고(외부 데이터 스토어)와 다양한 요리책(예시와 도구)을 가진 주방에 있을 때, 셰프는 거기서 필요한 재료와 책을 꺼내와 고객 레시피와 취향에 더 잘 맞는 요리를 만들어냄.
- Fine-tuning based learning : 셰프를 학교에 다시 보내 새로운 요리(특정 데이터셋 기반의 학습)를 배우게 했을 때, 이후 고객이 내는 다양한 레시피를 더 깊이 이해하고 더 전문적으로 요리를 할 수 있게 됨.
각 접근법은 속도, 비용, 지연(latency) 측면에서 서로 다른 장점과 단점을 갖는다. 하지만 이들을 조합하면 각 방식의 강점을 살리고 약점을 최소화하여 더 강력하고 적응력 있는 솔루션을 만들 수 있다.
Summary
이 백서에서는 생성형 AI 에이전트의 기본 구성 요소(foundational building blocks), 그들의 조합, 그리고 그들을 인지 아키텍처(cognitive architectures) 형태로 구현하는 방법을 다루었다.
핵심 포인트는 다음과 같다 :
- 에이전트는 tool을 이용해 실시간 정보 접근하고, 행동을 제안하고, 복잡한 task를 자율적으로 계획하고 수행함으로써 언어 모델의 능력을 확장시킨다. 에이전트는 하나 또는 하나 이상의 언어 모델을 활용해 추론, 계획, 실행 같은 단계들 사이를 언제, 어떻게 오갈지 결정할 수 있다. 또한, 외부 도구를 이용해 모델 혼자만으로는 해결하기 어렵거나 불가능한 작업을 수행할 수 있습니다.
- 에이전트 작동의 핵심은 추론·계획·의사결정·행동을 조율하는 인지 아키텍처인 오케스트레이션 레이어이다. ReAct, Chain-of-Thought(CoT), Tree-of-Thoughts(ToT)와 같은 추론 기법은 오케스트레이션 레이어가 정보를 받아들이고, 내부적으로 추론하며, 근거 있는 의사결정을 하게끔, 또 응답을 생성하게끔 도움을 준다.
- Extensions, Functions, Data Stores는 에이전트가 외부 세계와 연결되는 열쇠 역할을 한다. Extension은 에이전트 ↔ 외부 API 사이의 다리 역할을 하여 실시간으로 API를 호출할 수 있도록 돕는다. Function은 역할 분담을 통해 개발자에게 더 세밀한(nuanced) 제어권을 제공할 수 있으며, A에이전트가 함수 실행에 필요한 파라미터만 생성하고 실제 실행은 클라이언트 측에서 이루어지도록 할 수 있다. Data Store는 구조적·비구조적 데이터로의 접근을 지원, 데이터에 기반한 애플리케이션을 구현할 수 있게 해준다.