MCP: The Illustrated Guidebook 리뷰
MCP란 무엇인가?
당신이 오직 영어만 할 줄 안다고 상상해보자. 프랑스어만 할 줄 아는사람과 대화하려면 프랑스어를 배워야만 한다. 독일어만 할 줄 아는 사람과 대화하려면 독일어를 배워야만 한다. 만약 5가지 언어를 배워야만 한다면? 바로 악몽의 시작이다. 하지만 만약 모든 언어를 이해할 수 있는 번역가를 고용한다면?
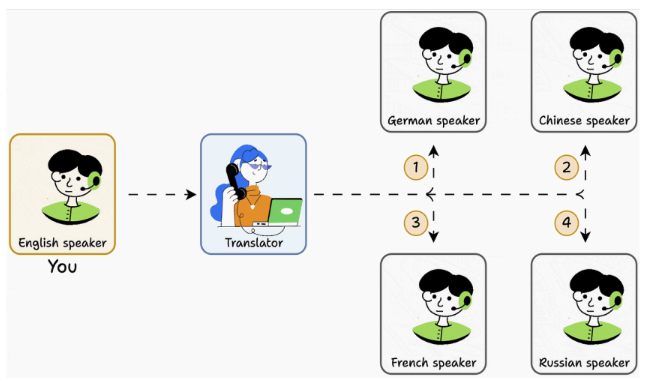
아주 심플해졌다. MCP는 번역가다. 당신(Agent)이 한 가지의 인터페이스만 가지고 있으면 다른 사람들(tool 또는 다른 기능들)과 얘기할 수 있다. LLM이 많은 지식과 추론이 가능할지라도, 그 지식은 학습 데이터에 국한되어있다.

만약 실시간 정보에 접근해야 한다면 에이전트는 스스로 외부 툴과 리소스를 사용해야만 한다. MCP는 AI 모델이 외부 툴, 리소스, 환경과 매끄럽게 상호작용 할 수 있도록 해주는 표준화된 인터페이스이자 프레임워크이다.
MCP는 범용적인 커넥터처럼 동작한다. 예를 들어 USB-C 타입이 모든 전자기기들과 연결되는 것과 같다.
MCP는 왜 만들어졌는가?
MCP가 없었을 때는 새로운 툴이나 모델을 추가하는게 골칫거리였다. 만약 3가지의 AI 애플리케이션과 3가지의 외부 툴이 있다면, 표준 없이는 9가지의 다른 모듈을 만들어야 한다(AI 애플리케이션 개수 X 툴 개수). 이 방식은 확장성이 없다.
AI 앱 개발자들은 사실상 매번 바퀴를 다시 발명하는 셈이었고, 툴 제공자들은 서로 호환되지 않는 여러 API들을 지원해야만 다양한 AI 플랫폼에 연결할 수 있었다. 즉, 툴 제공자들은 여러 플랫폼마다 제각각의 API를 맞추느라 고생했었다.
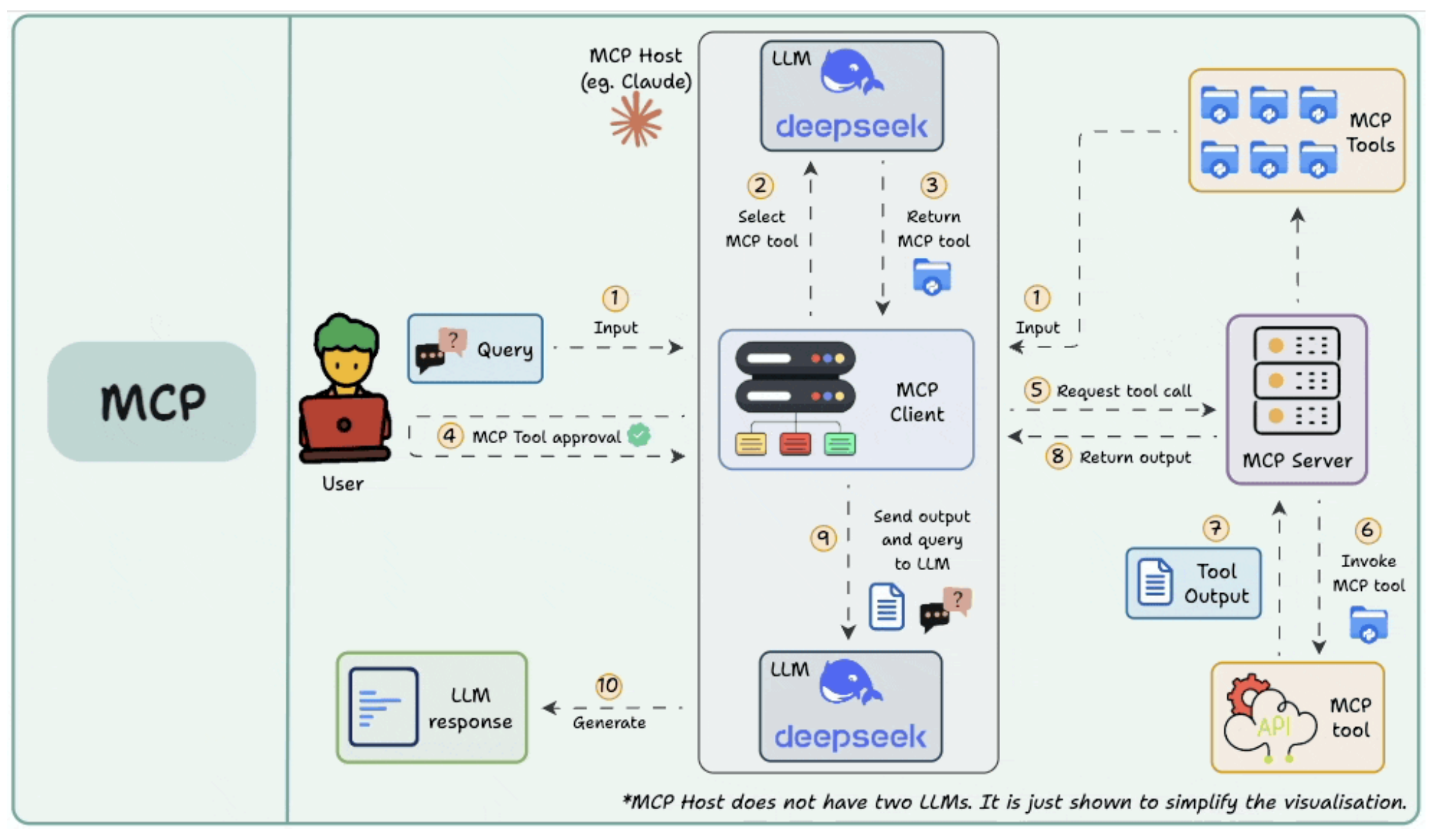
MCP 호스트가 실제로 LLM을 두 개 가지는 것은 아니다. 단지 시각화를 쉽게 하려고 그렇게 표시한 것
갑자기 이 그림이 튀어나온다. 일단 해석을 하자면
전체 구조
- 왼쪽(User 영역): 사용자가 질의를 입력.
- 가운데(MCP Client & LLM 영역): LLM이 어떤 MCP 툴을 쓸지 결정 → MCP 클라이언트가 MCP 서버와 통신.
- 오른쪽(MCP Server & Tools 영역): MCP 서버가 툴을 호출하고, 결과를 클라이언트에 반환.
- 최종 결과: LLM이 응답을 생성해 사용자에게 돌려줌.
단계별 흐름 (1~10)
- Input : 사용자가 질의(Query)를 입력. 예: “최신 환율 알려줘”
- Select MCP tool : LLM이 어떤 MCP 툴을 사용할지 선택. 예: “Currency API 툴을 써야겠다.”
- Return MCP tool : LLM이 선택한 MCP 툴 정보를 MCP 클라이언트에 전달.
- MCP Tool approval : 사용자가 툴 사용을 승인.(안전장치: LLM이 임의로 툴을 호출하지 못하도록 사람이 승인하는 구조도 가능)
- Request tool call : MCP 클라이언트가 MCP 서버에 “이 MCP 툴을 실행해 달라” 요청.
- Invoke MCP tool : MCP 서버가 실제 MCP 툴(API, DB, 파일 시스템 등)을 호출.
- Tool Output : MCP 툴이 결과를 생성. 예: “1 USD = 1,350 KRW”
- Return output : MCP 서버가 MCP 클라이언트로 툴 실행 결과를 반환.
- Send output and query to LLM : MCP 클라이언트가 툴의 출력 + 원래 사용자 질문을 LLM에 전달.
- Generate : LLM이 최종 응답을 생성해 사용자에게 전달. 예: “현재 달러-원 환율은 1,350원입니다.”
아래에서 좀 더 디테일하게 알아보자.
Problem
문제는 이렇다. MCP가 나오기 전에는, AI를 외부 데이터나 행동에 연결하는 방식이 전부 제각각이었다. 툴 하나마다 하드코딩된 로직을 따로 짜야 했고, 안정적이지도 않은 프롬프트 체인을 직접 관리해야 했으며, 아니면 특정 벤더 전용 플러그인 프레임워크에 묶여버리곤 했다.
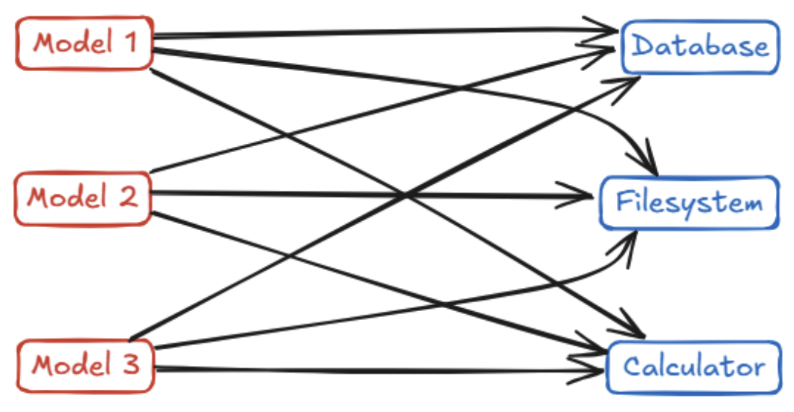
그 결과 악명 높은 M×N 통합 문제가 생겼다. 즉, AI 애플리케이션이 M개 있고, 툴이나 데이터 소스가 N개 있다면, M × N 개수만큼의 커스텀 통합 코드를 만들어야 했다. 각각의 AI가 각각의 외부 서비스(DB, 파일시스템, 계산기 등)와 대화하려면 전부 서로 다른 전용 코드를 따로 준비해야 한다. 결국 여기저기 복잡하게 얽힌 코드 더미가 생기고, 시스템은 마치 스파게티처럼 꼬여버린다. AI ↔ 외부 툴 연결 구조가 표준 없이 제멋대로여서, 수십~수백 개의 맞춤 연결을 직접 짜야 했고, 그게 바로 M×N 문제라는 악몽이었다.
Solution
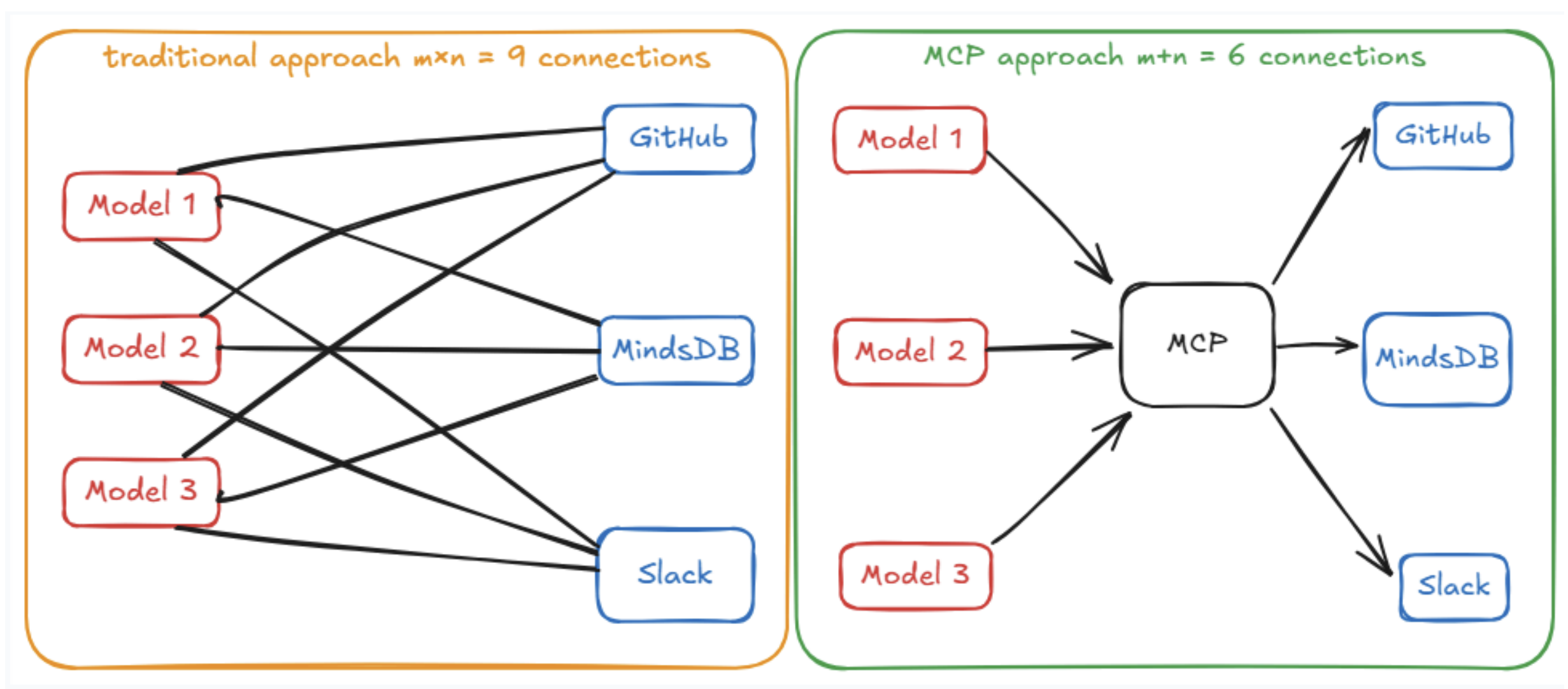
MCP는 중간에 표준 인터페이스(통역사 같은 역할)를 도입한다. 그 전까지는 AI 애플리케이션 M개 × 툴 N개 = M×N개의 맞춤 통합 코드를 전부 따로 짜야 했다. 하지만 MCP를 쓰면 이렇게 바뀐다:
- AI 애플리케이션 M개는 각각 MCP 클라이언트 언어만 배우면 되고,
- 툴 N개는 각각 MCP 서버 언어만 배우면 된다.
즉, 총합은 M+N으로 줄어든다. 이제는 모두가 “MCP”라는 세계 공용어를 쓴다. 그래서 새로운 AI-툴 짝을 만들 때마다 새로운 코드를 짤 필요가 없다. 왜냐하면, 이미 서로 MCP라는 공용 언어를 통해 알아들을 수 있기 때문이다.
MCP Arcitecture Overview
MCP의 핵심은 클라이언트-서버 아키텍처를 따른다는 것이다. (웹이나 다른 네트워크 프로토콜과 유사하다.) 다만, 용어는 AI 맥락에 맞게 조정되어 있다. 이해해야 할 세 가지 주요 역할은 다음과 같다: Host, Client, Server.
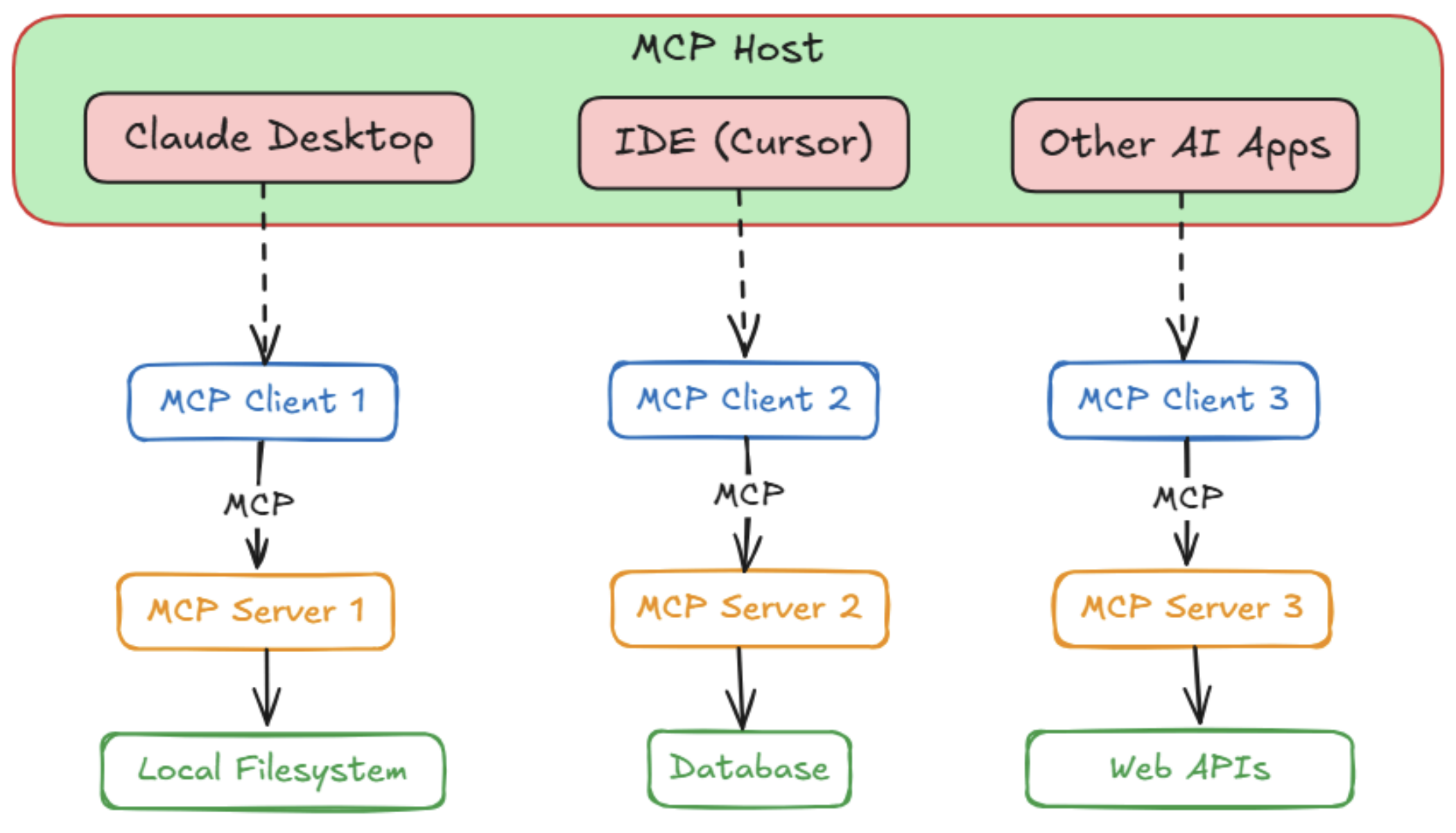
Host
Host는 유저를 대면하는 AI 애플리케이션을 의미한다. 즉, AI 모델이 존재하고 사용자와 상호작용하는 환경을 말한다.
OpenAI의 ChatGPT 인터페이스나 Anthropic의 Claude 데스크톱 앱 같은 채팅 애플리케이션이 될 수도 있고, Cursor와 같은 AI 기반 IDE일 수도 있으며, Chainlit처럼 AI 어시스턴트를 임베드한 커스텀 앱일 수도 있다.
지금 시스템이 MCP를 필요로 할 때, Host가 현재 available한 MCP 서버와 연결을 최초로 맺어주는 역할을 한다. 또한 유저의 인풋을 캡처하고, 대화 기록을 유지하며 모델의 응답을 display한다.
Client
MCP 클라이언트는 Host의 구성 요소 중 하나다. MCP 서버와 low-level로 커뮤니케이션한다. 어댑터 또는 메신저라고 생각하면 된다. Host가 무엇을 할 지 지시사항을 결정한다면, Client는 MCP라는 언어를 아는 존재로써, 그 지시사항을 서버에 보내고, 응답을 받는 역할을 한다.
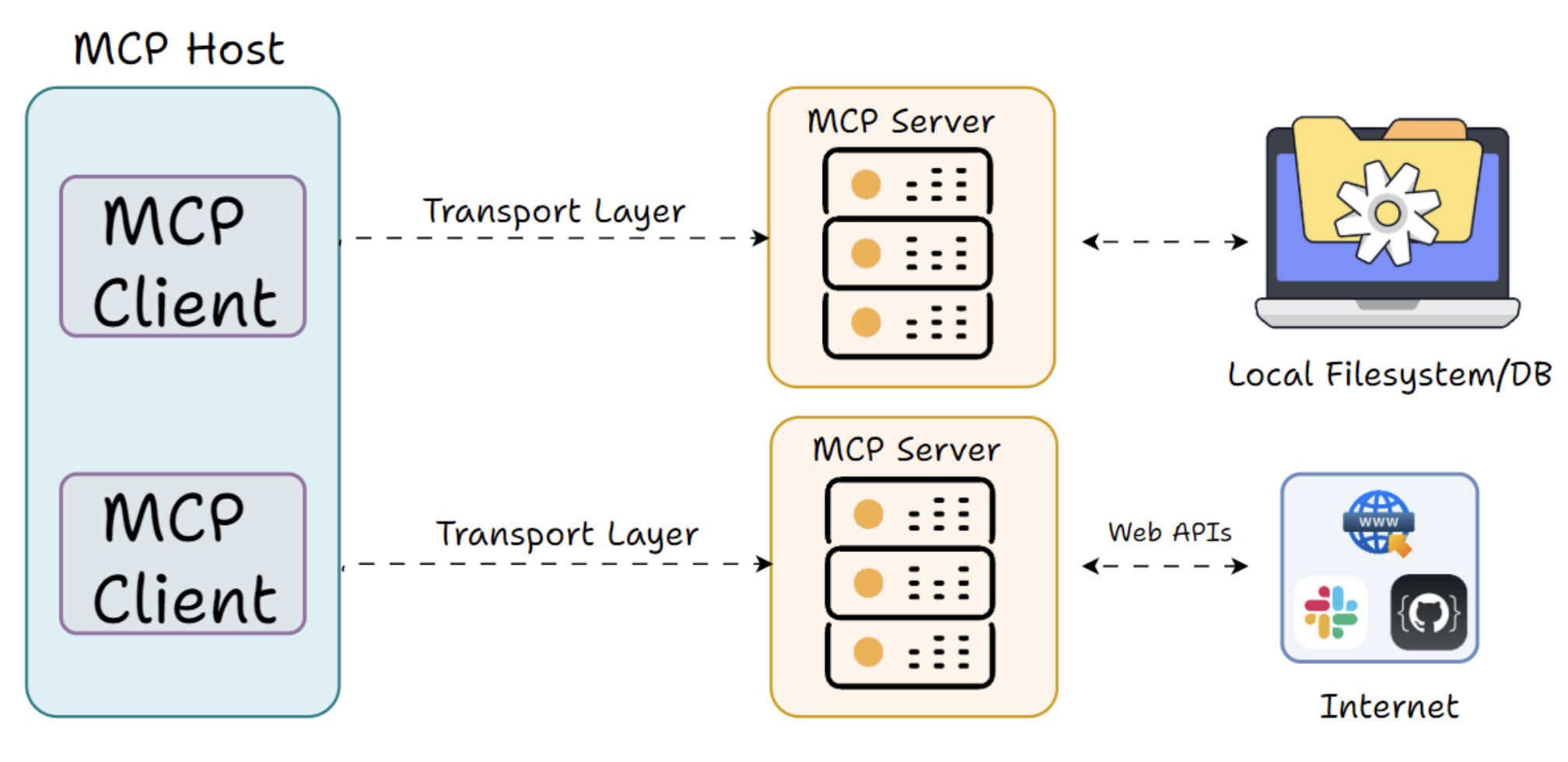
Server
Server는 애플리케이션에 툴, 데이터 등의 기능을 실제로 제공하는 외부 프로그램이나 서비스를 의미한다.
MCP 서버는 몇 가지의 기능(capabilities)을 표준화된 방식으로 감싸서 노출하는 일종의 래퍼(wrapper)로 이해할 수 있다. 즉, 어느 MCP 클라이언트라도 호출할 수 있는 액션 또는 리소스의 집합이다.
로컬하게 Host와 같은 머신에서 실행될 수도 있고, 클라우드 서비스처럼 원격에서 실행될 수도 있다. MCP는 두 가지 시나리오를 모두 지원하도록 설계되어 있다.
중요한 점은, 서버는 자신이 무엇을 할 수 있는지 표준화된 형식으로 스스로를 광고하여, 클라이언트가 사용 가능한 툴을 조회할 수 있게, 또 클라이언트의 요청을 처리하여 결과를 응답할 수 있도록 한다는 것이다.
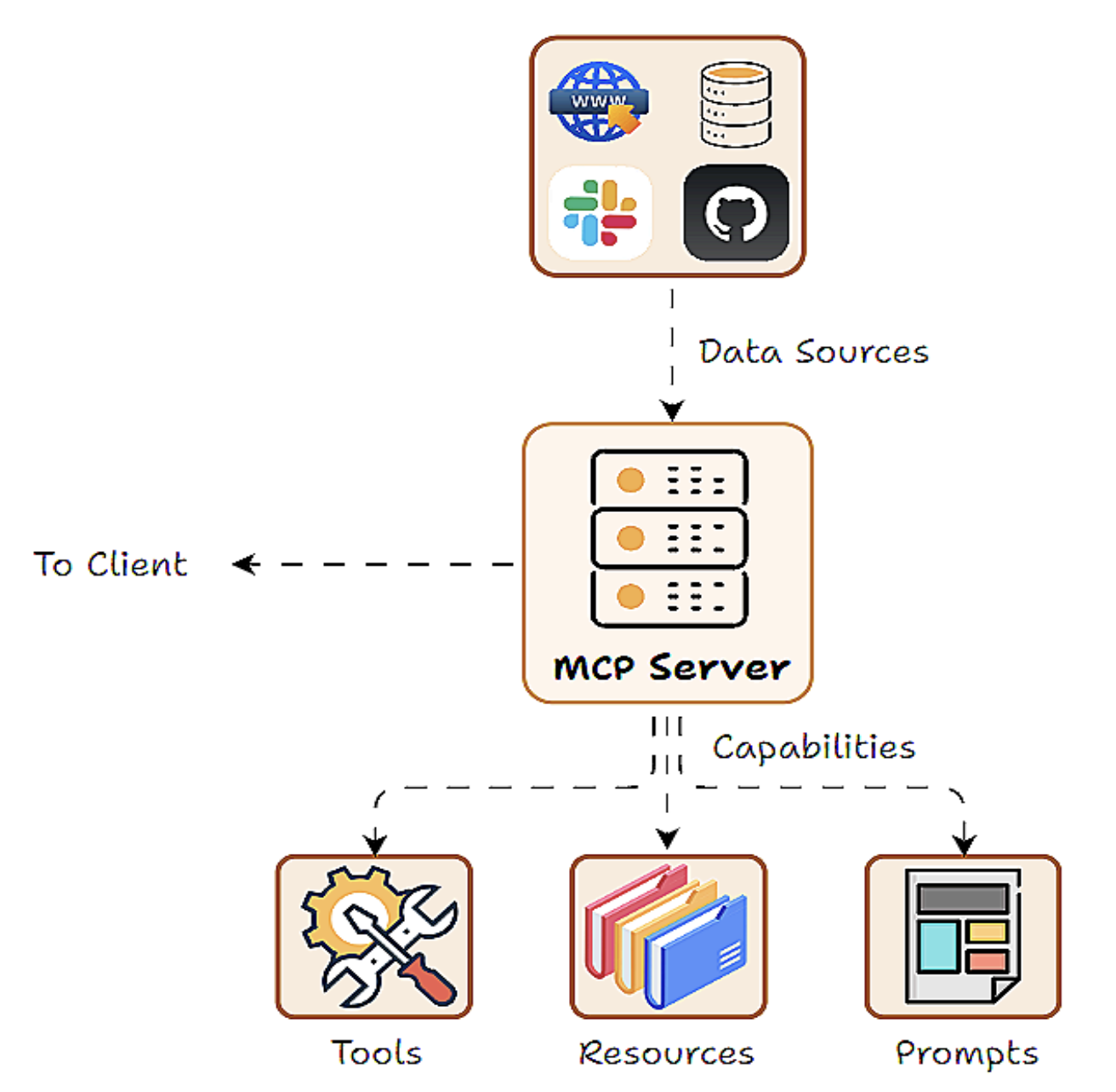
Tools, Resources and Prompts
도구(Tools), 프롬프트(Prompts), 리소스(Resources) ― 이 세 가지가 MCP 프레임워크의 핵심 기능(capabilities)을 이룬다. 여기서 Capability란, 서버가 외부에 제공하는 기능이나 역할을 의미한다.
- Tools (도구): AI(Host/Client)가 호출할 수 있는 실행 가능한 액션이나 함수. 보통 외부 API 호출을 의미. 시스템에 영향을 주는 작업(side effect)도 포함한다.
- 프로그래밍에서의 Side Effect 의미는 함수가 단순히 결과값을 반환하는 것 외에, 시스템의 상태에 변화를 일으키는 것, 즉, 외부 세계에 영향을 미치는 행위를 의미한다. Tool은 외부 API 호출, 파일 쓰기, DB 업데이트처럼 “환경에 변화를 주는 작업”을 포함할 수 있음
- Resources (리소스): AI(Host/Client)가 조회할 수 있는 Read-Only 데이터 소스. Side effect는 없고, 단순히 정보만 가져온다.
- Prompts (프롬프트): 서버가 제공할 수 있는 미리 정의된 프롬프트 템플릿이나 워크플로우.
Tools
이름 그대로 도구, 즉 AI 모델을 대신해 무언가를 수행하는 함수들이다. 보통 AI 자체의 능력만으로는 처리할 수 없는 연산이나 외부에 영향을 미치는 작업들이 여기에 해당한다.
중요한 점은, Tools는 보통 AI 모델의 선택에 의해 실행된다는 것이다. 즉, LLM이 특정 기능이 필요하다고 판단하면 Host를 통해 해당 Tool을 호출한다.
예를 들어 간단한 날씨 조회 툴이 있다고 해보자. MCP Server 코드 안에서는 이런 식으로 구현될 수 있다.

이 파이썬 함수는 @mcp.tool() 데코레이터로 등록되어 있으며, AI가 MCP를 통해 호출할 수 있다.
예를 들어 AI가 tools/call을 호출하면서 이름을 "get_weather"로, 인자를 {"location": "San Francisco"}로 전달하면, 서버는 get_weather("San Francisco")를 실행하고 그 결과를 딕셔너리 형태로 반환한다.
MCP Client는 이 JSON 결과를 받아 AI가 활용할 수 있도록 제공한다. 여기서 중요한 점은 툴이 구조화된 데이터(예: 온도, 날씨 상태)를 반환한다는 것이다. 그러면 AI는 그 정보를 활용하거나 자연어 응답으로 표현할 수 있다.
또한 툴은 파일 입출력(file I/O)이나 네트워크 호출 같은 작업을 수행할 수 있기 때문에, MCP 구현에서는 종종 유저 툴 호출을 허용을 요구한다.
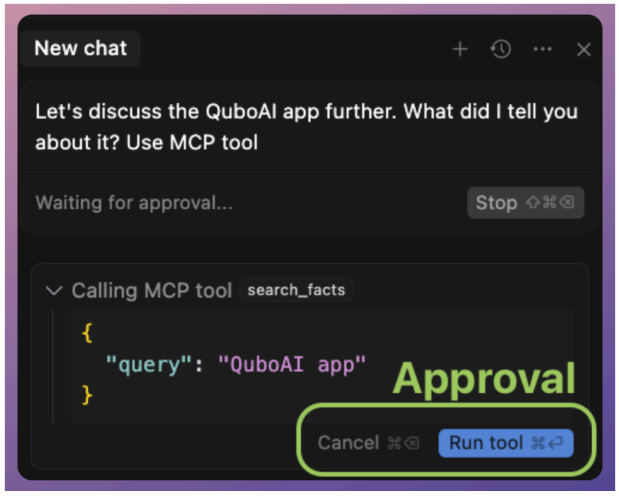
정리하면, MCP 툴은 AI → Client → Server를 통해 호출되고, 구조화된 JSON 결과를 돌려주는 구조.
예를 들어, Claude의 클라이언트는 첫 호출 시 “AI가 ‘get_weather’ 툴을 사용하려고 합니다. 허용하시겠습니까? (예/아니오)” 같은 팝업을 띄워 남용을 방지할 수 있다. 이렇게 함으로써 강력한 액션에 대해서는 인간이 통제권을 유지하게 된다.
Resources
AI 모델에 읽기 전용 데이터를 제공하는 기능이다. 쉽게 말해 데이터베이스나 지식 베이스 등을 말하는데, 모델이 정보를 가져올 수는 있지만, 직접 수정하거나 삭제할 수는 없다.
툴과는 다르게, 리소스는 일반적으로 복잡한 연산이나 외부 세계에 영향을 주는 작업(side effect)을 말하진 않고, 단순히 정보를 조회하는 용도에 가깝다.
또 하나의 중요한 차이점은 접근 방식인데, 리소스는 보통 호스트 애플리케이션이 제어한다(모델이 스스로 호출하는 것은 아니고). 예를 들어 호스트가 대화 맥락을 보고 “이 상황에서는 유저 프로필 데이터를 불러와야겠다”라고 판단해 해당 정보를 모델에 전달하는 식이다.
결국 리소스는 단순한 정보 공급원이며, 언제 어떤 데이터를 가져올지는 호스트가 결정하는 구조라고 할 수 있다.
예를 들어 유저가 “회사 핸드북을 참고해서 내 질문에 답해줘”라고 말한다면, 호스트는 관련된 핸드북 섹션을 가져오는 리소스를 호출해 모델에 전달할 수 있다.
리소스는 로컬 파일의 내용, 지식 베이스나 문서에서 발췌한 일부, Read-only인 데이터베이스 조회 결과, 혹은 설정 정보 같은 정적인 데이터 등일 수 있다.
즉, 모델이 맥락(Context)으로 알아야 할 만한 거의 모든 것을 리소스로 제공할 수 있다는 뜻이다. 예를 들어 AI 연구 보조 에이전트는 “ArXiv 논문 데이터베이스”를 리소스로 두고, 요청이 들어오면 논문 초록이나 참고 문헌을 가져올 수 있다. 가장 단순한 형태의 리소스는 파일을 읽어오는 함수일 수도 있다.
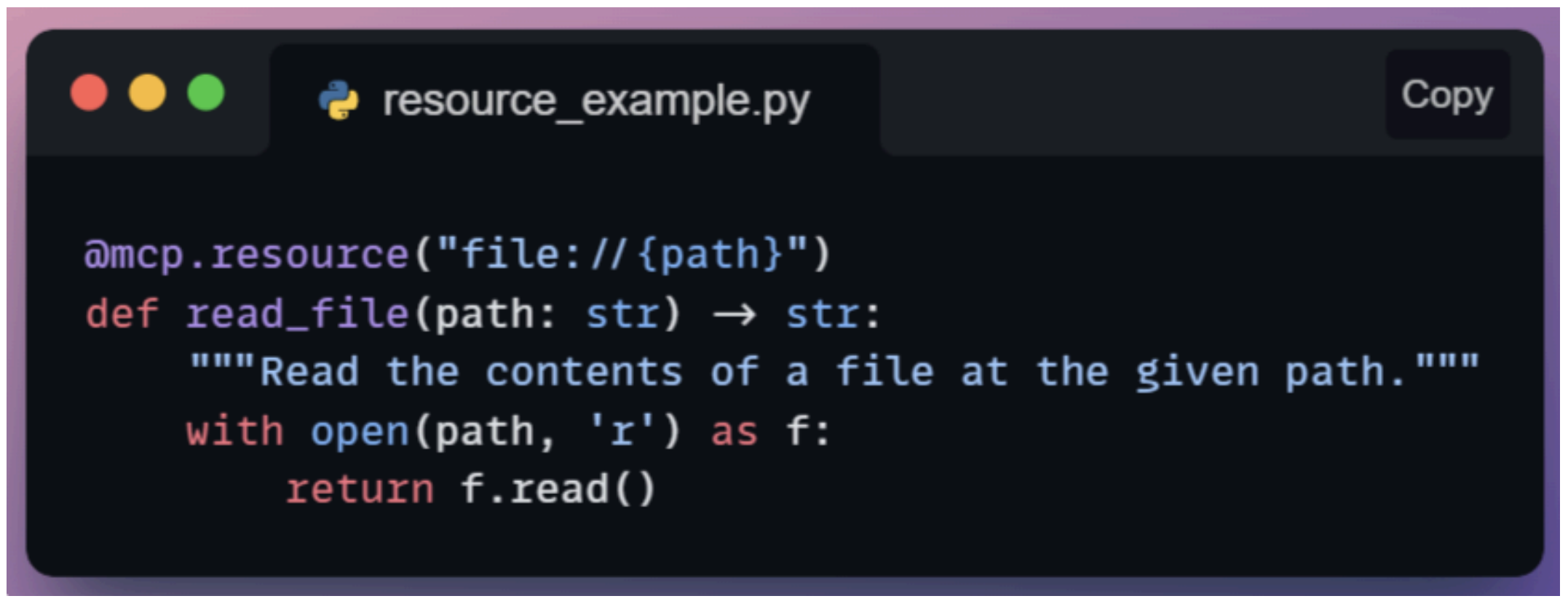
여기서는 @mcp.resource("file://{path}")라는 데코레이터를 사용하는데, 이는 리소스 URI를 정의하는 템플릿 역할을 한다고 볼 수 있다.
AI(혹은 호스트)는 MCP Server에 resources.get 요청을 보낼 수 있는데, 예를 들어 file://home/user/notes.txt 같은 URI를 지정하면, 서버는 내부적으로 read_file("/home/user/notes.txt")를 호출하고 그 결과 텍스트를 반환한다.
중요한 점은, 리소스는 보통 자유로운 형태의 함수 호출이 아니라 URI나 이름 같은 identifier로 식별된다는 것이다.
리소스는 보통 애플리케이션이 제어한다. 즉, 모델이 임의로 아무 데이터나 읽는 것을 방지하기 위해, 언제 어떤 리소스를 가져올지는 앱이 결정한다는 뜻이다.
안전 측면에서 보면, 리소스는 읽기 전용이기 때문에 상대적으로 위험성이 적지만, 그래도 개인정보 보호나 접근 권한 같은 요소는 반드시 고려해야 한다. 예를 들어 AI가 허용되지 않은 파일을 읽게 해서는 안 된다. 이를 위해 호스트는 AI가 접근할 수 있는 리소스 URI를 제한할 수 있고, MCP Server 역시 특정 데이터에 대한 접근을 막을 수 있다.
정리하면, 리소스는 AI에게 어떤 것도 바꿀 수 있는 권한을 주지 않고 오직 지식만 제공한다. MCP 안에서 리소스는 모델에 참조 자료(reference material)를 필요할 때 건네주는 역할을 하며, 이는 곧 더 똑똑하고 필요할 때 불러올 수 있는 검색 시스템을 프로토콜 안에 통합한 것이라고 볼 수 있다.
Prompts
Prompts(프롬프트)는 MCP 맥락에서 조금 특별한 개념이다. 이는 미리 정의된 프롬프트 템플릿이나 대화 흐름을 의미하며, 모델의 행동을 특정 방향으로 유도하는 역할을 한다. 쉽게 말해, 프롬프트 기능은 특정 작업을 수행할 때 모델을 안내하기 위해 사전에 만들어 둔 지침이나 예시 대화 세트를 제공하는 것이다.
그렇다면 왜 프롬프트를 별도의 기능(capability)로 두는 걸까?
이는 반복적으로 자주 등장하는 패턴을 다루기 위함이다. 예를 들어 “너는 코드 리뷰어다”라는 시스템 role을 설정하고, 유저가 작성한 코드를 분석하도록 모델을 안내하는 프롬프트가 있다면, 이걸 매번 호스트 애플리케이션에 하드코딩하지 않고 MCP 서버에서 제공할 수 있다.
또한 프롬프트는 단순한 한두 줄 지침을 넘어서, 여러 차례에 걸친 대화(workflow)도 정의할 수 있다. 예를 들어 단계별로 유저와 진단 인터뷰를 진행하는 방식의 프롬프트를 MCP 서버에서 제공한다면, 어떤 클라이언트든 필요할 때 이 프롬프트를 불러와 활용할 수 있다.
프롬프트 사용 주체를 보면, 보통 유저나 개발자가 제어한다.
예를 들어 유저가 UI에서 “이 문서를 요약해줘”라는 프롬프트 템플릿을 고르면, 호스트가 서버로부터 해당 프롬프트를 가져와 모델에 전달하는 식이다. 중요한 점은, 모델이 자발적으로 프롬프트를 선택하지 않는다는 것이다(반면 툴은 자발적으로 선택했었다). 프롬프트는 모델이 응답을 생성하기 전에 무대를 세팅해주는 역할을 한다. 그래서 보통 대화의 시작이나 유저가 특정 “모드”가 선택할 때 호출된다.
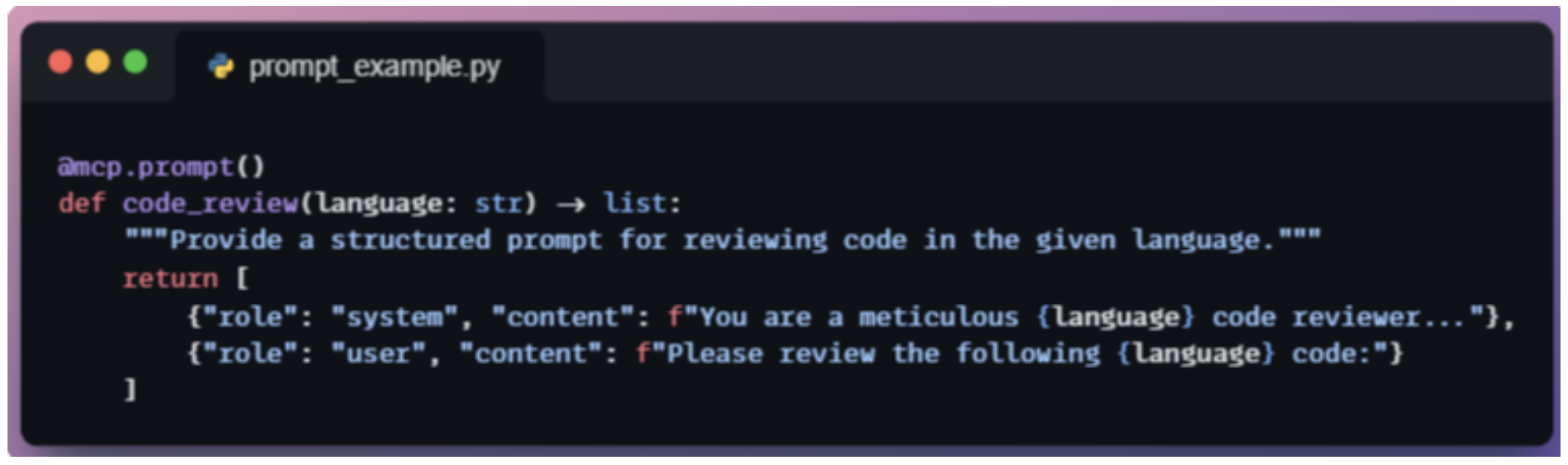
예를 들어, 코드 리뷰용 프롬프트 템플릿이 있다고 하자.
MCP Server에는 이 프롬프트가 코드 리뷰 시나리오를 설정하는 메시지 객체(OpenAI의 message 객체같은)를 반환하는 함수로 정의돼 있을 수 있다. Host가 이 프롬프트를 불러오는 주체가 되어 MCP Server로부터 미리 정의된 메시지 세트를 받고, 메시지들이 준비되고, 실제 리뷰 대상 코드가 삽입되고, 모델은 이 메시지를 받아 답변을 생성한다. 즉, MCP Server가 대화의 기본 구조(프롬프트 템플릿)를 마련해주는 셈이다.
아직 이 기능이 크게 활용된 사례는 많지 않지만, 대표적인 활용 예시로는 브레인스토밍 가이드, 단계별 문제 해결 템플릿, 특정 도메인에 특화된 시스템 역할 등이 있다. 프롬프트가 MCP Server에 정의돼 있으면, 클라이언트 앱을 수정하지 않고도 서버 쪽에서 업데이트하거나 개선할 수 있고, 서버마다 다른 특화된 프롬프트를 제공할 수도 있다.