E5-Mistral을 이용한 임베딩 추출 모델
안녕하세요! AI 리서치 엔지니어 김현우입니다.
이번 월간수도렉 주제로 저희 팀에서 준비하고 있는 “E5-Mistral을 이용한 임베딩 추출 모델”에 대해 공유드리려 합니다.
저희는 기본적으로 RAG를 이용하여 영화의 메타 정보를 가져오고, 이를 기반으로 LLM과 결합시켜 Chatbot 형태의 추천시스템을 만드려고 계획하고 있습니다. 그렇다면, 이때 RAG를 이용해서 영화의 메타 정보 및 내용을 가져와야하고 이때 이를 위한 자연어 처리 or 임베딩 모델이 필요합니다.
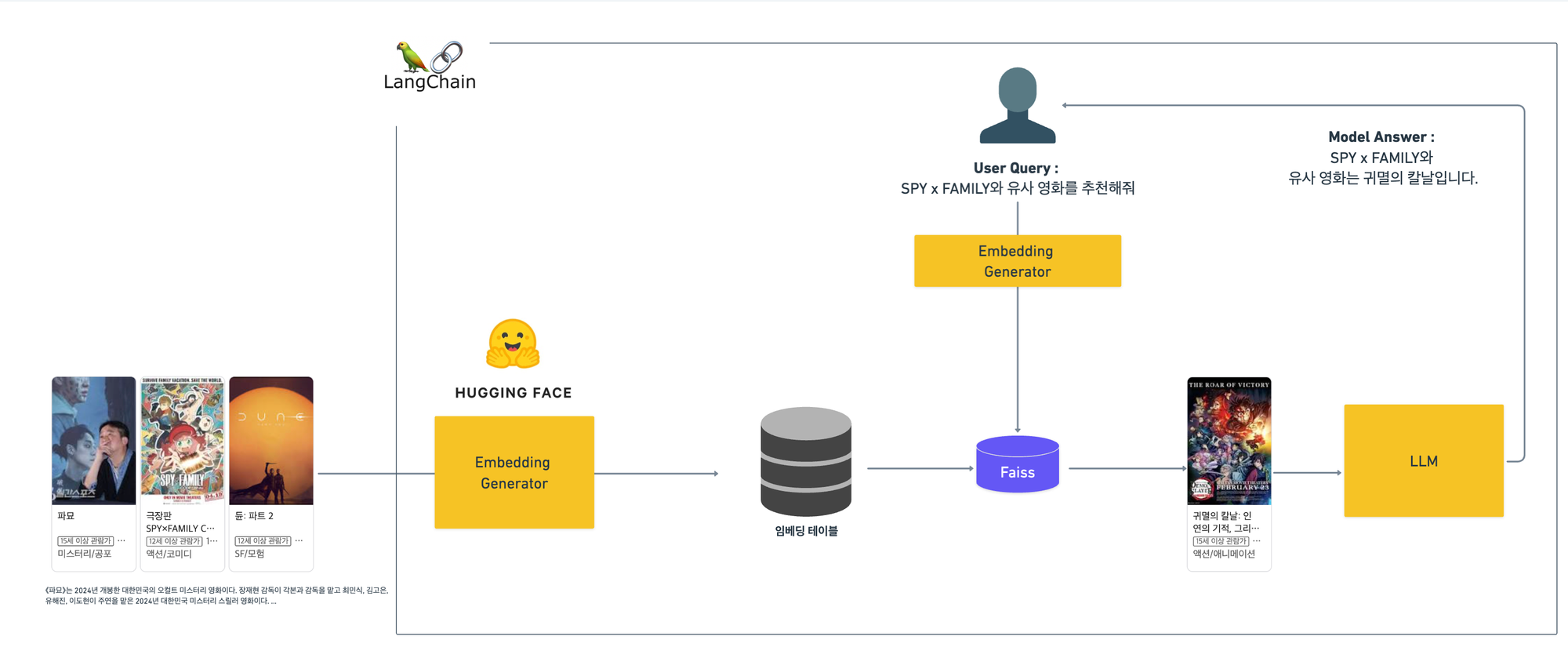
실제 위의 그림에서 왼쪽의 파트라고 생각하시면 됩니다. 그렇다면, 현재 RAG에서 임베딩 추출은 어떻게 진행이 되고 있을까요?
일반적으로는 Huggingface 상에 공개된 임베딩 모델을 가져와서 하게 됩니다. 해당 모델들은 자연어 입력이 들어오면 아래와 같이
def last_token_pool(last_hidden_states: Tensor, attention_mask: Tensor) -> Tensor: left_padding = (attention_mask[:, -1].sum() == attention_mask.shape[0]) if left_padding: return last_hidden_states[:, -1] else: sequence_lengths = attention_mask.sum(dim=1) - 1 batch_size = last_hidden_states.shape[0] return last_hidden_states[torch.arange(batch_size, device=last_hidden_states.device), sequence_lengths] outputs = model(**batch_dict) embeddings = last_token_pool(outputs.last_hidden_state, batch_dict['attention_mask'])
last_hidden_states 을 추출해서 임베딩을 추출하게 되는 구조입니다.
그러면 우리는 HuggingFace에 있는 라마, 솔라 등의 모델을 가져와서 위의 코드로 임베딩을 추출하면 끝일까요?
반반만 맞습니다. 그렇게 해도 주어진 입력을 임베딩 공간상에 매핑해서 활용한다는 점에서 사용이 불가능한 것은 아니지만, 우리가 원하는 목적과는 다를 수 있습니다. 우리가 원하는 목적은 유사한 영화 정보가 비슷한 임베딩 공간상에 모이도록 해야하는데 실제 공개된 모델들은 그렇지 않은 경우가 많기 때문입니다.
그렇다면 이를 위해서 어떤 작업을 해줘야하나요? 비슷한 문서는 비슷한 임베딩을 가지도록 추가 학습이 필요하고, 이를 적용한 대표적인 논문이 E5-Mistral 이라는 논문입니다.
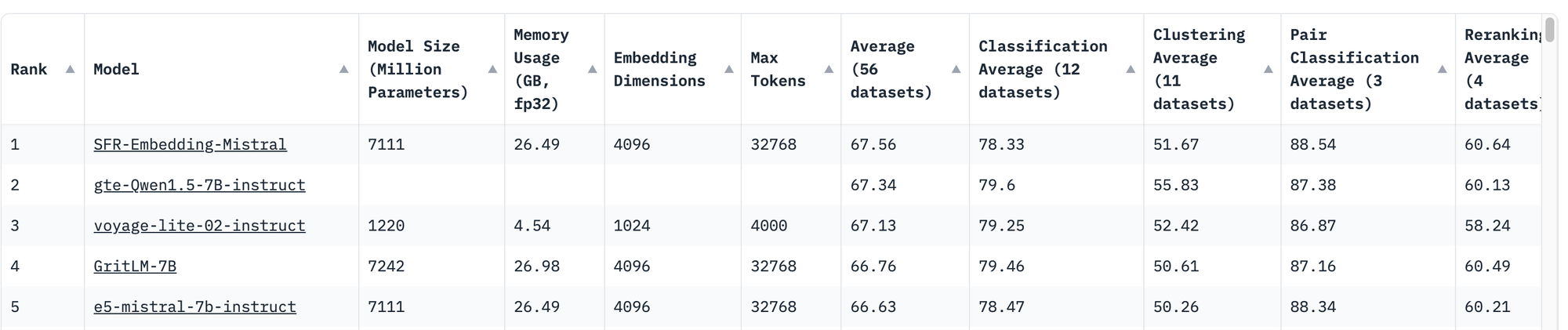
해당 방법은 MTEB 이라는 임베딩 리더보드에서 상위권의 모델로 간단한 방법을 통해서도 높은 성능을 달성한 모델입니다.
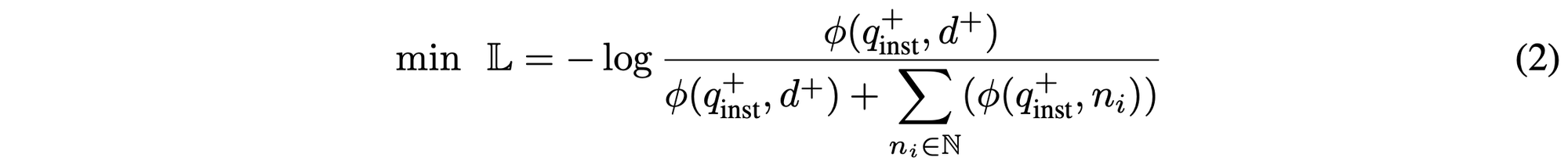
그럼 어떻게 해당 방법이 높은 성능을 달성할 수 있었을까요? 그 방법은 로스의 구성에 있습니다.
해당 논문에서 사용하는 로스는 InfoNCE로스라고 Metric Learning 방법의 로스를 사용합니다.
실제 수식을 보면 알겠지만, 주어진 Query와 연관이 있는 Document+와 연관이 없는 Document (ni)를 기반으로 로스를 계산 하게 됩니다. 이때, 학습 방법은
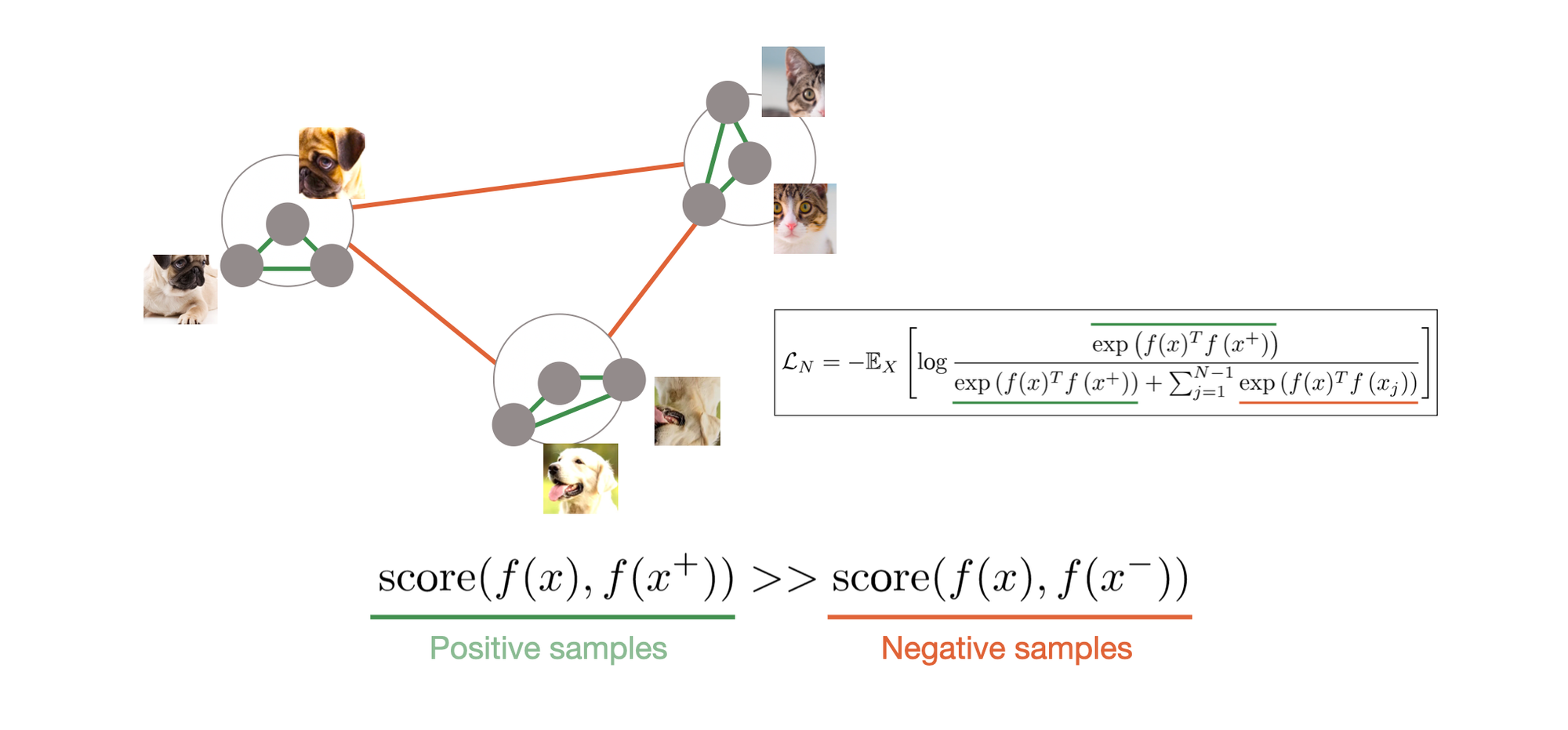 출처 : 🔗 https://nuguziii.github.io/survey/S-006/ ↗
출처 : 🔗 https://nuguziii.github.io/survey/S-006/ ↗
Positive samples 간에 거리는 가깝게, Negative Samples간의 거리는 멀게 학습되어서 저희가 원하는 유사 영화끼리 같은 임베딩 상에 매핑되도록 도와줍니다.
아직 계획중이지만 저희는 실제 해당 코드를 이용해서 백본 모델을 학습해가지고, 실제 유사 영화의 임베딩이 잘 추출되는지 다음에 확인해보려고 합니다 🙂
이제까지 글 읽어주셔서 감사합니다.