NGCF 구현기
📄 paper : Neural Graph Collaborative Filtering ↗
※ 수식이 깨져보이신다면 새로고침을 해주세요
Model
NGCF 프레임워크
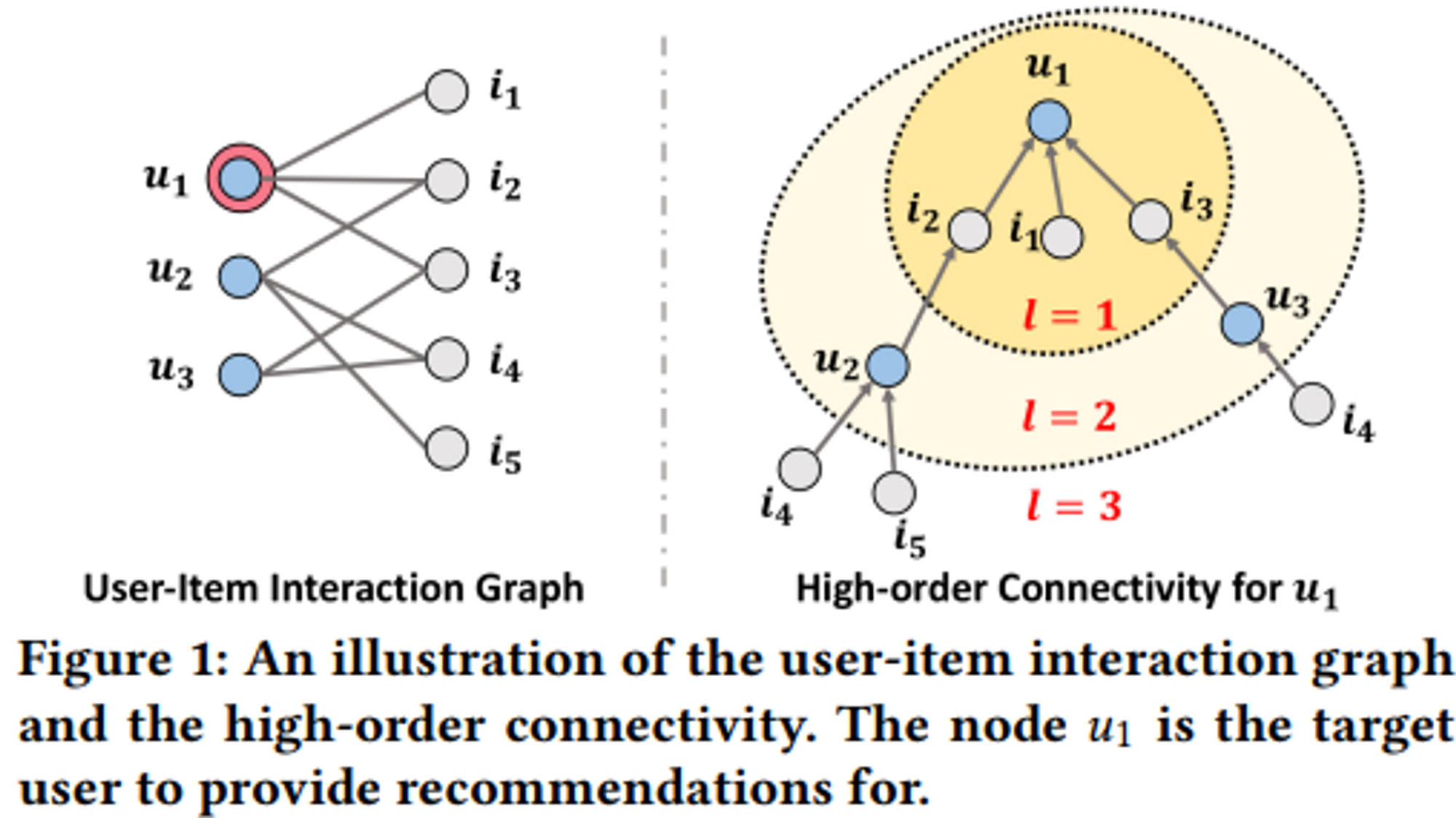
Figure 1의 좌측은 user와 item간의 interaction graph, 우측은 High-order Connectivity를 나타냄.
User-Item Interaction Graph : $u_1$ → {$i_1$, $i_2$, $i_3$}, $u_2$ → {$i_2$, $i_4$, $i_5$}
High-order Connectivity : $u_1$ → $i_2$ → $u_2$ → {$i_4$, $i_5$}, $u_1$ → $i_3$ → $u_3$ → {$i_4$}
$u_1$이 $i_5$보다 $i_4$에 더 큰 관심을 가질 가능성이 높음.
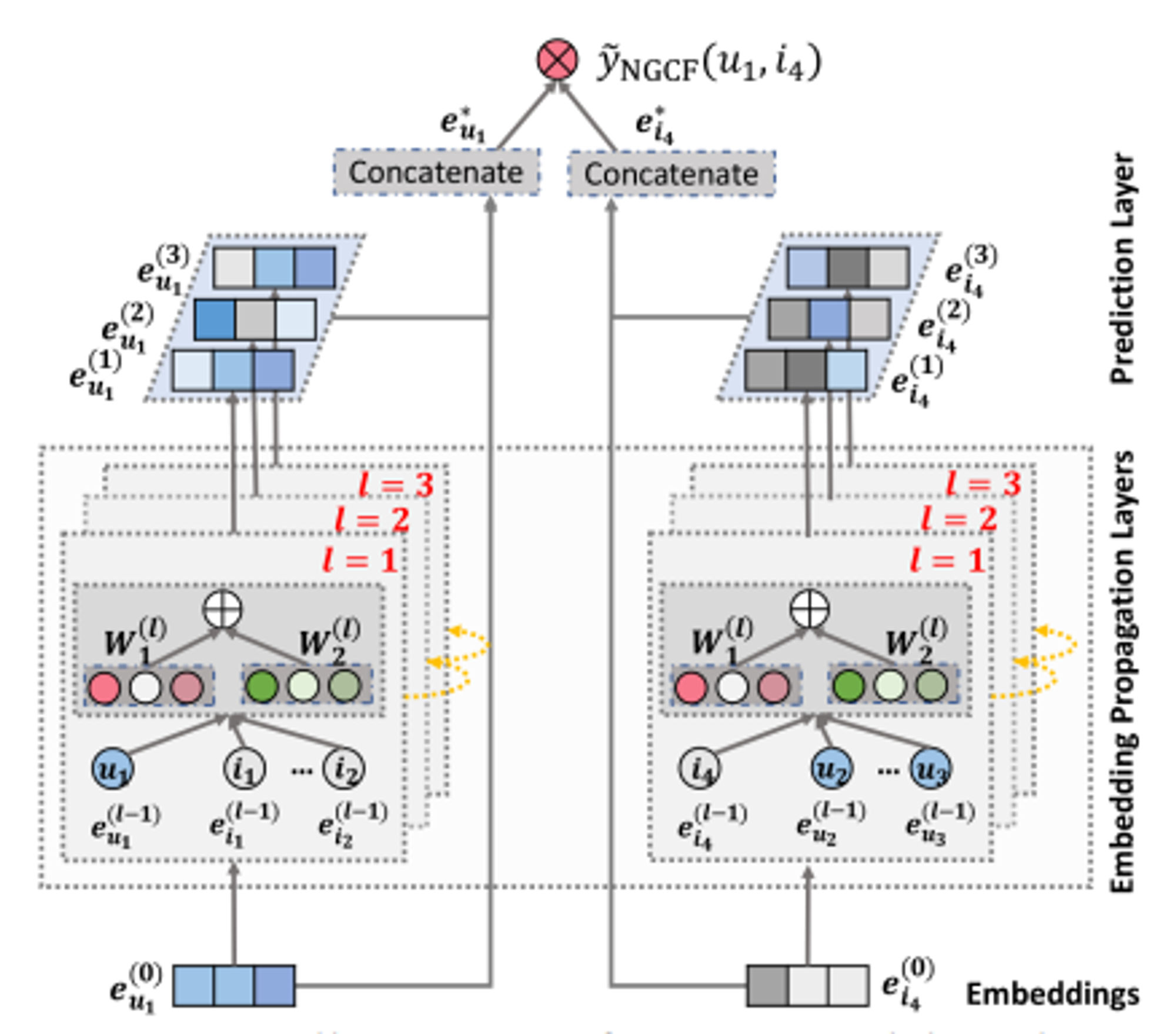
그래프 구조를 통해 CF signal을 캡쳐하기 위해서 GNN의 message-passing architecture 를 구축해서 user, item 임베딩을 refine 함.
refine된 user와 item의 임베딩 값을 내적하여 최종 값 도출.
최종 PseudoRec TASK)
유저와 상호작용이 존재하는 영화를 기반으로 추천 알고리즘을 적용하여 유저에게 영화 추천.
Training & Predict
ngcf_predictor.py
import pandas as pd import torch import numpy as np import dgl import dgl.function as fn import torch import torch.nn as nn import torch.nn.functional as F import torch.optim as optim from collections import OrderedDict import pytorch_models.ngcf.model from pytorch_models.ngcf.model import NGCF from pytorch_models.ngcf.utility.parser import parse_args import pytorch_models.ngcf.utility.metrics as metrics from pytorch_models.ngcf.utility.load_data import * from pytorch_models.ngcf.utility.batch_test import * import pytorch_models.Data.daum.train_test_split as ts class NgcfPredictor: def __init__(self): self.args = parse_args() self.device = 'cpu' self.num_recommendations = 10 self.num_epochs = 10 def sample(self, users, items): def sample_pos_items_for_u(u, num): # sample num pos items for u-th user pos_items = items n_pos_items = len(pos_items) pos_batch = [] while True: if len(pos_batch) == num: break pos_id = np.random.randint(low=0, high=n_pos_items, size=1)[0] pos_i_id = pos_items[pos_id] if pos_i_id not in pos_batch: pos_batch.append(pos_i_id) return pos_batch def sample_neg_items_for_u(u, num): # sample num neg items for u-th user neg_items = [] while True: if len(neg_items) == num: break neg_id = np.random.randint(low=0, high=3706, size=1)[0] if ( neg_id not in items and neg_id not in neg_items ): neg_items.append(neg_id) return neg_items pos_items, neg_items = [], [] for u in users: pos_items += sample_pos_items_for_u(u, 1) neg_items += sample_neg_items_for_u(u, 1) return users, pos_items, neg_items def predict(self, interacted_items): """ # 회원가입한 사용자 버전(새로 회원가입을 한 경우에는 유저 임베딩이 추가되기 때문에 이전에 배치 or 온라인 학습된 모델을 checkpoint라는 변수로 불러와서 유저의 수를 new_num_user 변수에 생성) -> 아직 고민해봐야함.. checkpoint = torch.load('NGCF.pkl') checkpoint_dict = dict(OrderedDict(checkpoint)) new_num_user = len(checkpoint_dict['feature_dict.user']) user_id = new_num_user + 1 print(user_id) """ print(f"interacted_items : {interacted_items}") # 비회원 데이터 적재 X user_id = 10538 print(user_id) data_generator.train_items[user_id - 1] = interacted_items new_user_item_dst = interacted_items new_user_item_src = [user_id - 1] * len(new_user_item_dst) user_selfs = list(range(user_id)) item_selfs = list(range(25139)) data_dict = { ("user", "user_self", "user"): (user_selfs, user_selfs), ("item", "item_self", "item"): (item_selfs, item_selfs), ("user", "ui", "item"): ( data_generator.user_item_src + new_user_item_src, data_generator.user_item_dst + new_user_item_dst), ("item", "iu", "user"): ( data_generator.user_item_dst + new_user_item_dst, data_generator.user_item_src + new_user_item_src), } num_dict = {"user": user_id, "item": 25139} data_generator.g = dgl.heterograph(data_dict, num_nodes_dict=num_dict) model = NGCF( data_generator.g, 64, [64, 64, 64], [0.1, 0.1, 0.1], 1e-5).to(self.device) optimizer = optim.Adam(model.parameters(), lr=self.args.lr) for epoch in range(self.num_epochs): loss, mf_loss, emb_loss = 0.0, 0.0, 0.0 users, pos_items, neg_items = self.sample(new_user_item_src, new_user_item_dst) u_g_embeddings, pos_i_g_embeddings, neg_i_g_embeddings = model( data_generator.g, "user", "item", users, pos_items, neg_items ) batch_loss, batch_mf_loss, batch_emb_loss = model.create_bpr_loss( u_g_embeddings, pos_i_g_embeddings, neg_i_g_embeddings ) optimizer.zero_grad() batch_loss.backward() optimizer.step() loss += batch_loss # torch.save(model.state_dict(),self.args.model_name) model.eval() rec_items = {} # all-item test item = torch.tensor(list(set(item_selfs) - set(new_user_item_dst))).to(self.device) u_g_embeddings, pos_i_g_embeddings, _ = model( data_generator.g, "user", "item", user_id - 1, item, [] ) rate_batch = ( model.rating(u_g_embeddings, pos_i_g_embeddings).detach().cpu() ) _, top_indices = torch.topk(rate_batch.view(-1), self.num_recommendations) recommended_items = item[top_indices] rec = [] for i in recommended_items: rec.append(i) rec_list = [item.item() for item in rec] recomm_result = [] for i in rec_list: recomm_result.append(ts.item_decoder[i]) print(f"ngcf recomm_result : {recomm_result}") return recomm_result ngcf_predictor = NgcfPredictor()
CODE 설명
새로운 user의 interaction 정보 추가
def predict(self, interacted_items): new_user_item_dst = interacted_items new_user_item_src = [user_id - 1] * len(new_user_item_dst) user_selfs = list(range(user_id)) item_selfs = list(range(25139)) data_dict = { ("user", "user_self", "user"): (user_selfs, user_selfs), ("item", "item_self", "item"): (item_selfs, item_selfs), ("user", "ui", "item"): ( data_generator.user_item_src + new_user_item_src, data_generator.user_item_dst + new_user_item_dst), ("item", "iu", "user"): ( data_generator.user_item_dst + new_user_item_dst, data_generator.user_item_src + new_user_item_src), }
- 기존 학습된 model에 저장된 user와 movie의 bipartite 그래프 정보에(data_generator.user_item_src, data_generator.user_item_dst) 새로운 user와 movie의 interaction 정보를(new_user_item_dst, new_user_item_src) 추가
Re-training
def predict(self, interacted_items): for epoch in range(self.num_epochs): loss, mf_loss, emb_loss = 0.0, 0.0, 0.0 users, pos_items, neg_items = self.sample(new_user_item_src, new_user_item_dst) u_g_embeddings, pos_i_g_embeddings, neg_i_g_embeddings = model( data_generator.g, "user", "item", users, pos_items, neg_items ) batch_loss, batch_mf_loss, batch_emb_loss = model.create_bpr_loss( u_g_embeddings, pos_i_g_embeddings, neg_i_g_embeddings ) optimizer.zero_grad() batch_loss.backward() optimizer.step() loss += batch_loss
- 10번의 epoch으로 재학습 진행. → negative sampling 으로 BPR LOSS 손실함수 사용!
Inference
def predict(self, interacted_items): model.eval() rec_items = {} # all-item test item = torch.tensor(list(set(item_selfs) - set(new_user_item_dst))).to(self.device) u_g_embeddings, pos_i_g_embeddings, _ = model( data_generator.g, "user", "item", user_id - 1, item, [] ) rate_batch = ( model.rating(u_g_embeddings, pos_i_g_embeddings).detach().cpu() ) _, top_indices = torch.topk(rate_batch.view(-1), self.num_recommendations) recommended_items = item[top_indices] rec = [] for i in recommended_items: rec.append(i) rec_list = [item.item() for item in rec] recomm_result = [] for i in rec_list: recomm_result.append(ts.item_decoder[i]) print(f"ngcf recomm_result : {recomm_result}") return recomm_result
그렇게 재학습된 모델을 model.eval() 추론모드로 변경하여 새로운 user가 상호작용한 movie를 제외한 모든 movie에 대해 점수를 추론하여 가장 높은 점수의 영화 top k 를 추천해줌.
MLOps
views.py
import json import os import time import pandas as pd from django.http import JsonResponse, HttpResponse from django.shortcuts import render from django.views.decorators.csrf import csrf_exempt from dotenv import load_dotenv from kafka import KafkaConsumer, KafkaProducer from clients import MysqlClient from db_clients.dynamodb import DynamoDBClient from movie.models import DaumMovies from movie.predictors.sasrec_predictor import sasrec_predictor # from movie.predictors.ngcf_predictor import ngcf_predictor from movie.predictors.kprn_predictor import kprn_predictor from movie.utils import add_past_rating, add_rank, get_username_sid, get_user_logs_df, get_interacted_movie_obs from utils.kafka import get_broker_url from utils.pop_movies import get_pop load_dotenv('.env.dev') broker_url = get_broker_url() producer = KafkaProducer(bootstrap_servers=[broker_url], value_serializer=lambda v: json.dumps(v).encode('utf-8')) mysql = MysqlClient() pop_movies_ids = get_pop(mysql) pop_movies = list(DaumMovies.objects.filter(movieid__in=pop_movies_ids).values()) pop_movies = sorted(pop_movies, key=lambda x: pop_movies_ids.index(x['movieid'])) table_clicklog = DynamoDBClient(table_name='clicklog') def ngcf(request): print(f"movie/ngcf view".ljust(100, '>')) username, session_id = get_username_sid(request, _from='movie/ngcf') user_logs_df = get_user_logs_df(username, session_id) if not user_logs_df.empty: # 클릭로그 있을 때 interacted_movie_ids = [int(mid) for mid in user_logs_df['movieId'] if mid is not None and not pd.isna(mid)] interacted_movie_obs = get_interacted_movie_obs(interacted_movie_ids) ngcf_recomm_mids = ngcf_predictor.predict(interacted_items=interacted_movie_ids) ngcf_recomm = list(DaumMovies.objects.filter(movieid__in=ngcf_recomm_mids).values()) # context 구성 context = { 'ngcf_on': True, 'movie_list': add_rank(add_past_rating(username=username, session_id=session_id, recomm_result=ngcf_recomm )), 'watched_movie': interacted_movie_obs, 'description1': 'NGCF 추천 영화', 'description2': "NGCF 추천결과입니다" "<br><a href='http://127.0.0.1:8000/paper_review/2/'>논문리뷰 보러가기↗</a>" } return render(request, "home.html", context=context) else: context = { 'movie_list': [], 'sasrec_on': True, 'description1': 'SASRec 추천 영화', 'description2': '기록이 없어 추천할 수 없습니다!\n인기 영화에서 평점을 매기거나 포스터 클릭 기록을 남겨주세요!' } return render(request, "home.html", context=context)