BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer
Abstract
추천 시스템에서 단방향 모델은 과거의 정보만을 사용해 예측을 진행합니다. 그러나 사용자의 행동은 텍스트나 시계열 데이터처럼 엄격한 순서가 존재하지 않습니다. 본 논문에서는 사용자의 행동 순서를 모델링하기 위해 양방향 context 정보를 고려하는 BERT4Rec을 제안합니다. 이 때, 학습 시 발생하는 정보의 유출을 줄이고 학습의 효율성을 위해 Cloze 라는 random masking 기법을 활용합니다.
1. INTRODUCTION
💡 In many real-world applications, users’ current interests are intrinsically dynamic and evolving, influenced by their historical behaviors.
사용자의 관심사는 과거 행동에 영향을 받아 동적으로 변합니다.
ex. 아이폰을 구매한 사용자는 다음에 아이폰 충전기를 구매할 수 있습니다. 갤럭시 충전기를 구매하진 않을 것입니다.
- 💡 To model such sequential dynamics in user behaviors, various methods have been proposed to make ***sequential recommendations*** based on users’ **historical interactions**. They aim to predict the successive item(s) that a user is likely to interact with given her/his past interactions.
사용자의 과거 상호작용을 기반으로 다음에 선택할 아이템을 예측하는 것을 Sequential recommendation이라고 합니다.
💡 The basic paradigm of previous work is to encode a user’s historical interactions into a vector using a **left-to-right sequential model** and make recommendations based on this hidden representation.
기존 접근법들은 이를 위해 사용자의 과거 상호작용만을 hidden representaion으로 생성하여 추천을 제공했습니다.
ex. Recurrent Neural Network (RNN)
이러한 방법은 다음과 같은 한계가 존재합니다 :
- 아이템에 대한 hidden representation이 과거의 정보만을 고려
- 기존에 사용한 모델들은 엄격한 순서가 있다고 여겨지는 데이터를 위해 고안된 모델
⇒ 반면, 사용자의 행동의 순서는 뒤바뀔 수 있음
💡 To address the limitations mentioned above, we seek to use a bidirectional model to learn the representations for users’ historical behavior sequences. Specifically, inspired by the success of **BERT** in text understanding, we propose to apply the deep bidirectional self-attention model to sequential recommendation.
위 문제를 해결하기 위해, 본 논문에서는 sequential recommendation에 **BERT** 모델을 활용하는 것을 제안합니다.
⇒ 과거와 미래 정보로부터 얻는 context를 모두 활용할 수 있음
💡 Jointly conditioning on both left and right context in BERT cause information leakage. To tackle this problem, we introduce the ***Cloze*** task to take the place of the objective in unidirectional models.
과거와 미래 정보를 활용하여 학습하게 되면 간접적으로 예측 아이템을 보게 됩니다. 이 문제를 해결하기 위해 **Cloze** 방법론을 제안합니다.
**Cloze**
랜덤하게 아이템을 [mask] 토큰으로 숨기고, context를 기반으로 해당 item의 id를 예측하는 학습 방법
⇒ 학습 데이터가 늘어나는 효과
💡 However, a downside of the Cloze task is that it is not consistent with the final task. To fix this, during the test, we a**ppend the special token “[mask]” at the end of the input sequence** to indicate the item that we need to predict, and then make recommendations base on its final hidden vector.
그러나 Cloze 방법론은 sequential 추천의 최종 목표와 일치하지 않습니다. 따라서 테스트 단계에서는 [mask] 토큰을 입력의 마지막에 추가하여 다음에 나타날 아이템을 예측하도록 합니다.
Contributions:
- 사용자의 행동 sequence를 Cloze task를 기반으로 bidirectional self-attention을 활용하여 인코딩
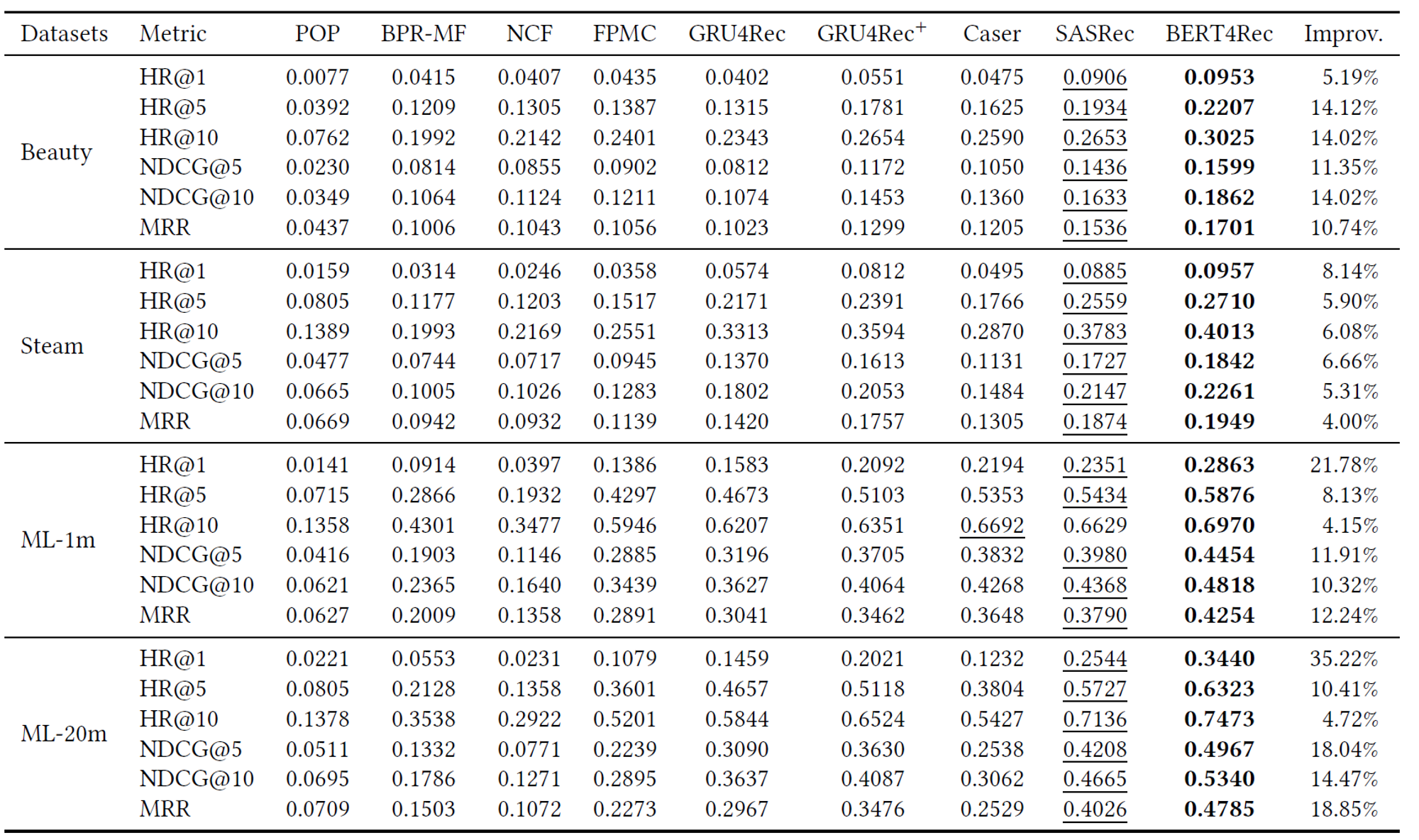
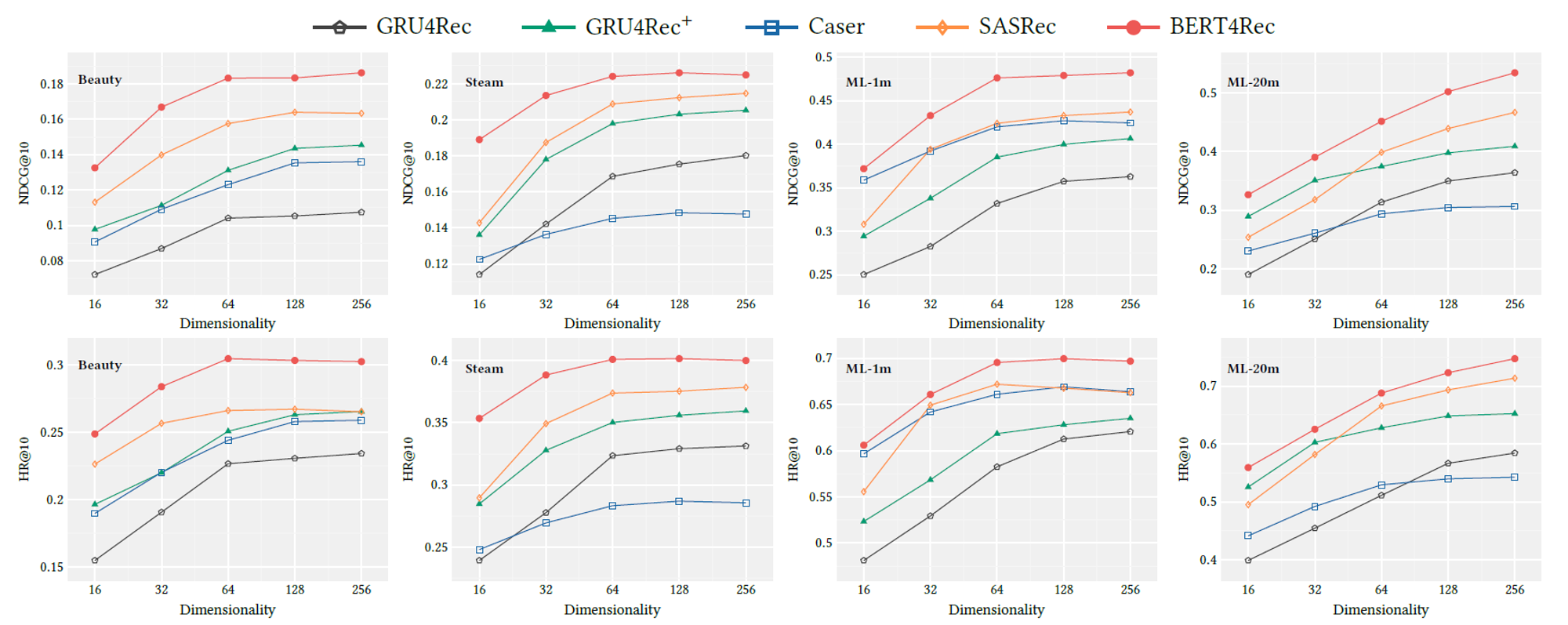
- 4개의 벤치마크 데이터셋에 대해 SOTA 모델들과 BERT4Rec 성능 비교
- BERT4Rec의 핵심 요소들이 성능에 미치는 영향을 분석
2. RELATED WORK
2.1. General Recommendation
- Collaborative Filtering (CF)
사용자의 ****과거 상호작용을 기반으로 추천 제공
- Matrix Factorization (MF) CF의 일종으로, user와 item을 공통된 vecotr space로 project하고 inner product를 통해 선호도 계산 ****
- Item-based neighborhood 과거 상호작용한 아이템 간의 similarity matrix을 바탕으로 추천 제공
- Deep learning based recommendation
- 추가적인 정보(text, images, acoustic features)를 CF 모델에 통합
- Matrix Factorization 대체
- Neural Collaborative Filtering (NCF) MF에서 inner product 대신 multi-layer perceptron (MLP)로 사용자 선호도 추정
- AutoRec, CDAE Auto-encoder 프레임워크를 기반으로 사용자 선호도 추정
2.2. Sequential Recommendation
상호작용의 순서를 고려하는 추천
- Markov Chains (MCs)
과거 상호작용으로부터 sequential patterns을 포착하여 추천 제공
- Markov Decision Processes (MDPs)
- Factorizing Personalized Markov Chains (FPMC) MCs와 MF를 결합하여 상호작용의 순서와 일반적인 선호도를 고려
- Deep Learning models
- Recurrent Neural Networks (RNN)
- Gated Recurrent Unit (GRU)
- session-based GRU with ranking loss (GRU4Rec)
- user-based GRU
- attention-based GRU (NARM)
- improved GRU4Rec with new loss function (BPR-max, TOP1-max)
- Long Short-Term Memory
- Gated Recurrent Unit (GRU)
- Convolutional Sequence Model (Caser) convolution 필터를 활용하여 상호작용의 순서에 존재하는 패턴 학습
- Memory Netork
- STAMP MLP와 attention을 활용하여 사용자의 일반적인 관심사와 현재 관심사를 포착
- Recurrent Neural Networks (RNN)
2.3. Attention Mechanism
- attention mechanism into GRU
- purely attention-based neural networks
-
- SASREC
- 2개의 Transformer decoder layer를 사용
- attention mask를 사용하여 여전히 unidirectional model ⇒ BERT4Rec은 bi-directional model로 Cloze task를 활용해 사용자의 행동을 encoding
-
3. BERT4REC
3.1 Problem Statement
$$ U = [u1,u2, . . . ,u_{|U|} ] $$
$$ V=[v1,v2, . . . ,v_{|V|}] $$
$$ Su=[v^{(u)}_1, . . . ,v^{(u)}_t, . . . ,v^{(u)}_{n_u}] $$
- 시계열 추천은 유저(u) 가 t + 1에서 상호작용할 아이템을 예측하는 것
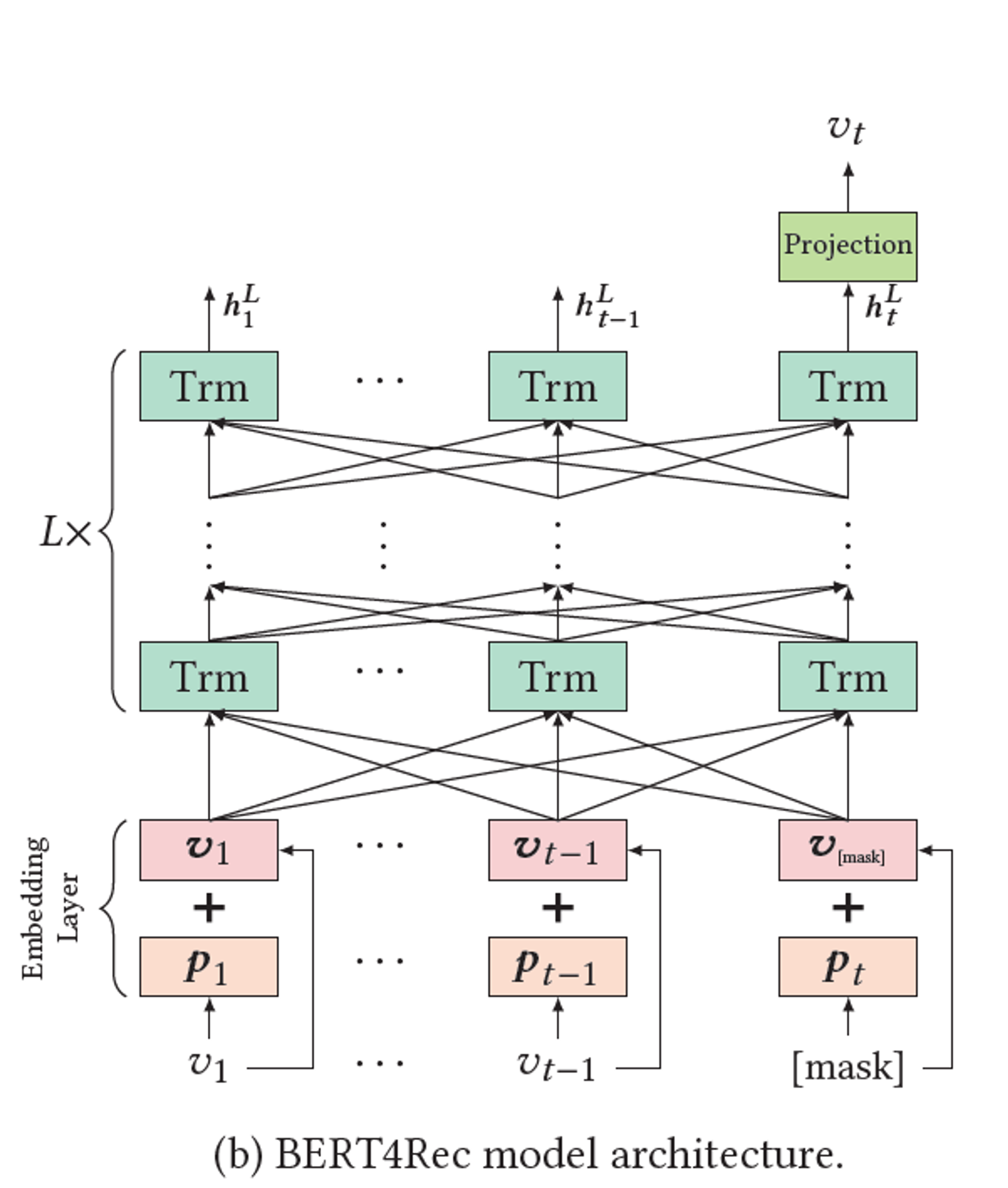
3.2 Model Architecture
-
Bidirectional Encoder Representations from Transformers to a new task, sequential Recommendation
3.3 Transformer Layer
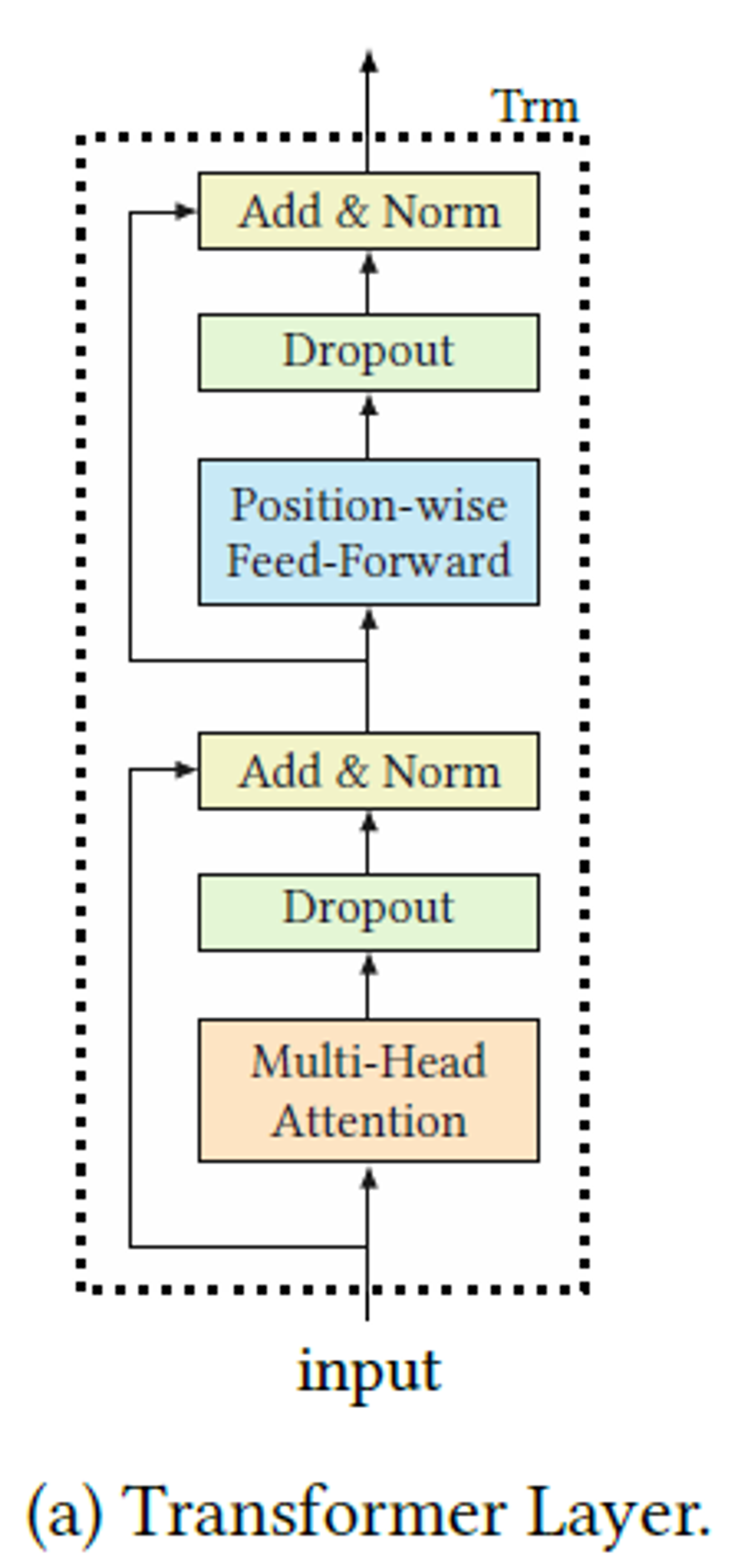
-
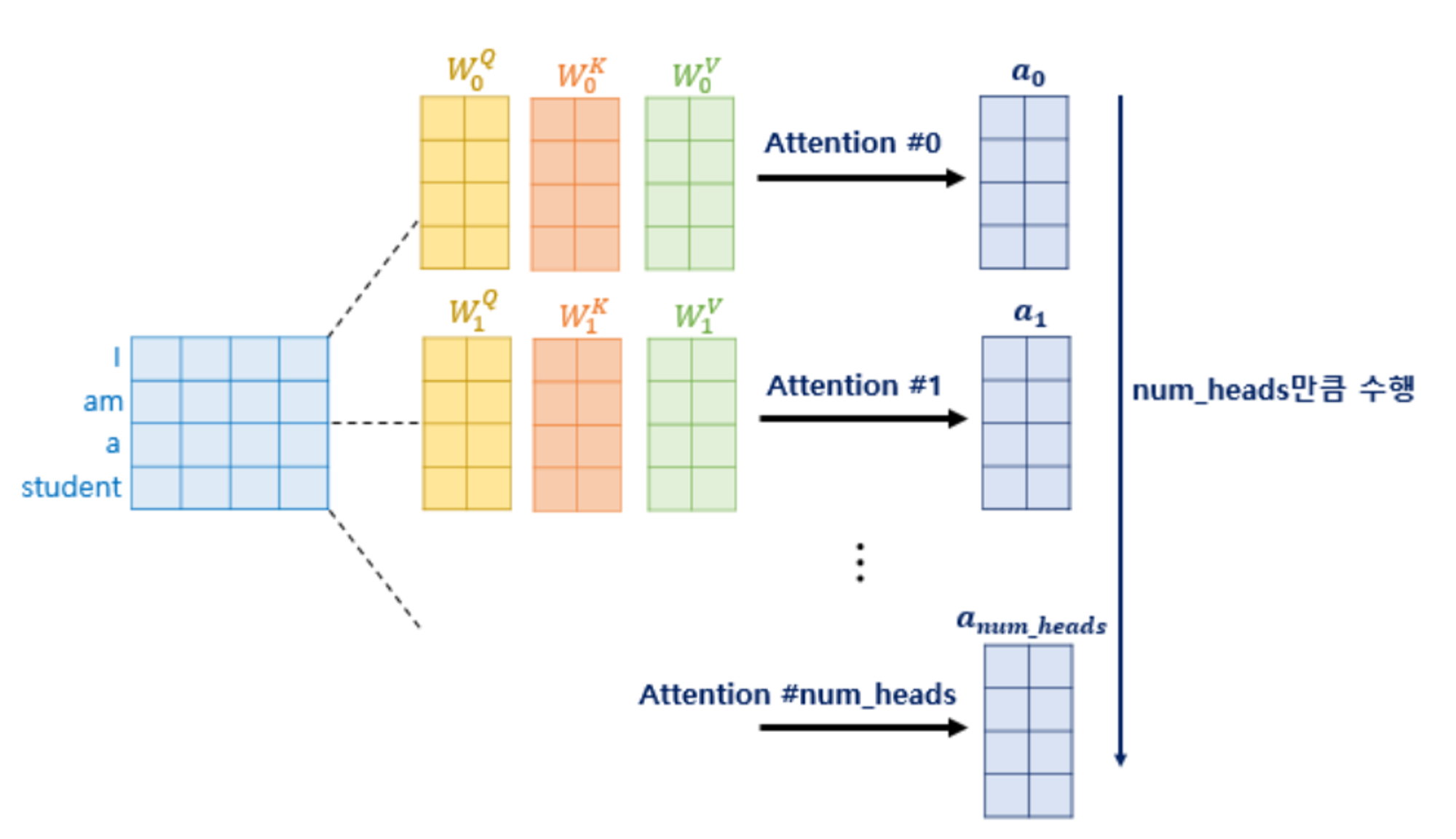
Multi-Head Self-Attention
$$ Attention(Q,K,V) = softmax(\frac{QK^T}{\sqrt{d/h}}) $$
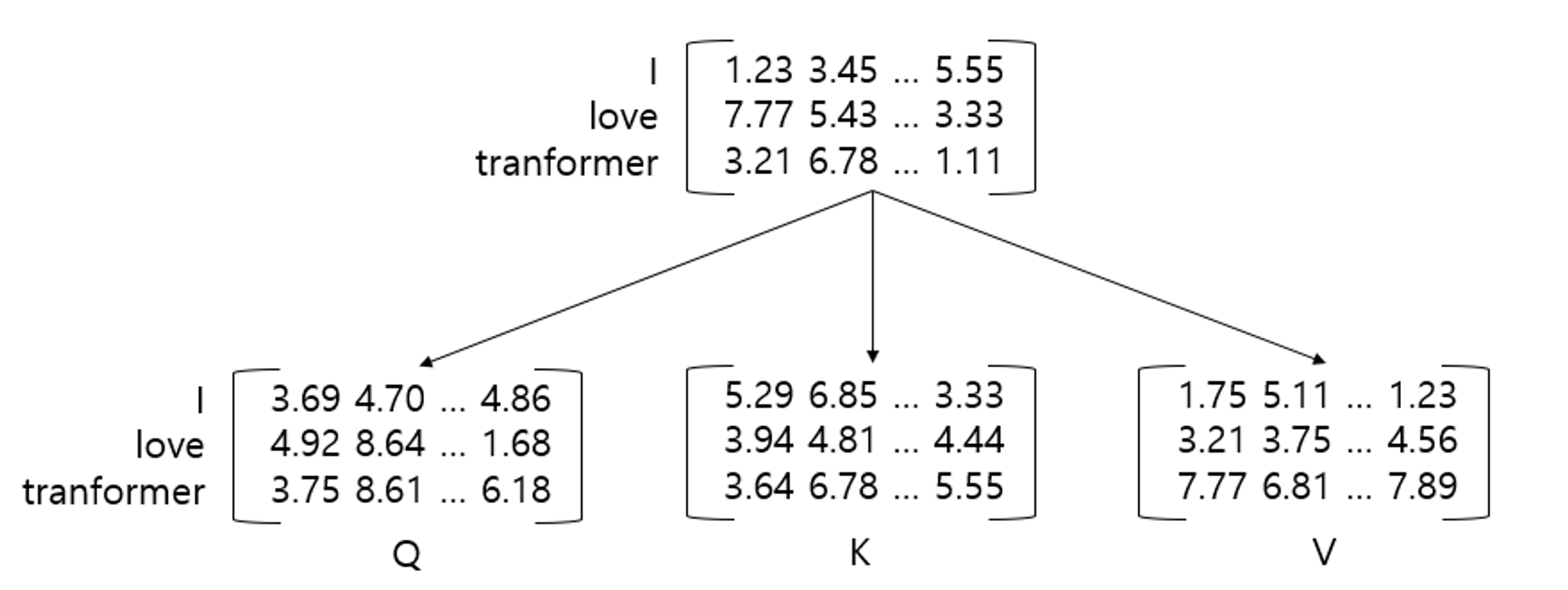

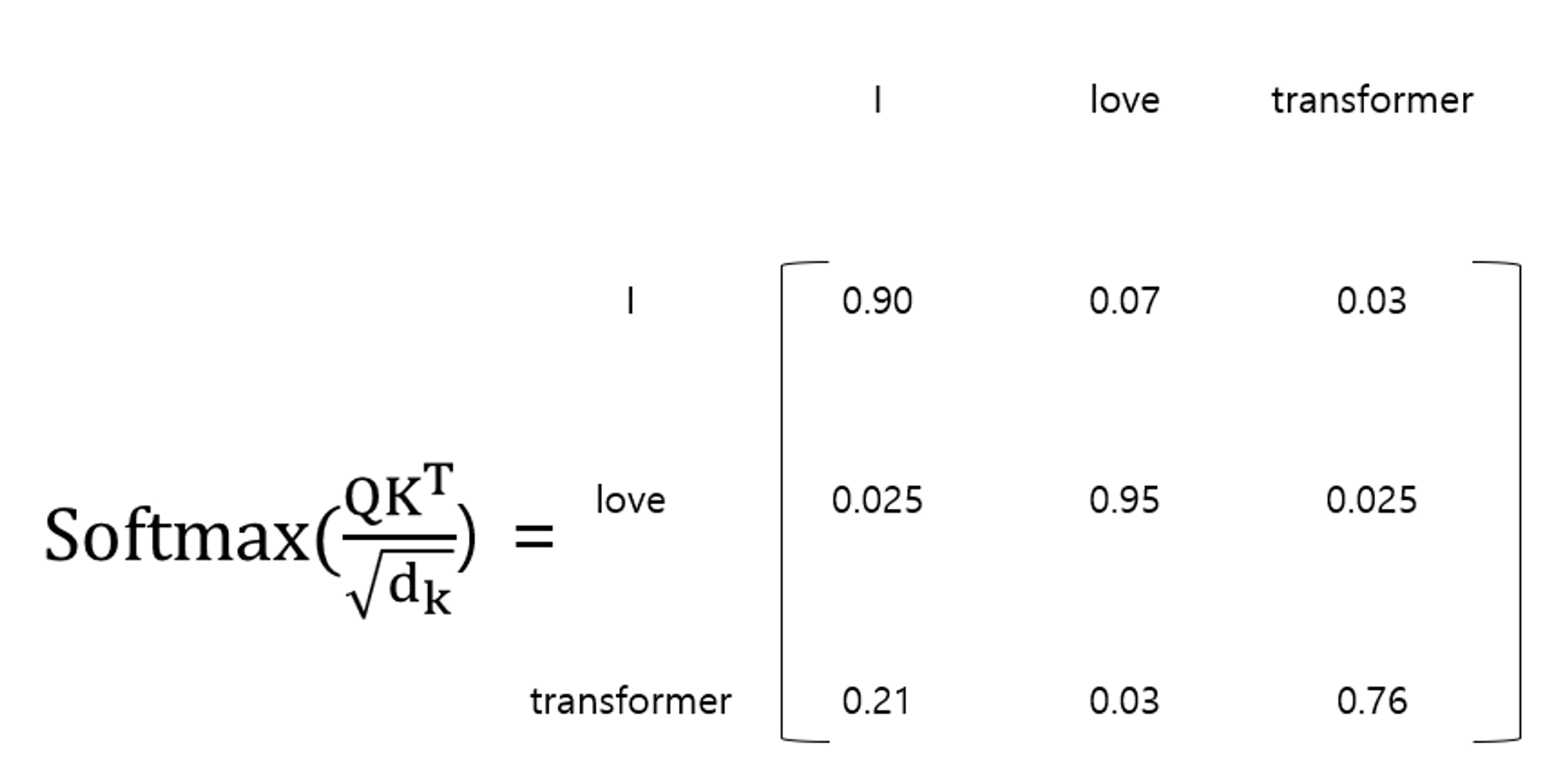
class Attention(nn.Module): def forward(self, query, key, value, mask=None, dropout=None): scores = torch.matmul(query, key.tranpose(-2, 1)) / math.sqrt(query.size(-1)) if mask is not None: scores = scores.masked_fill(mask == 0, -1e9) p_attn = F.softmax(scores, dim=-1) if dropout is not None: p_attn = dropout(p_attn) return torch.matmul(p_attn, value), p_attn
class MultiHeadAttention(nn.Module): """ 모델 크기와 헤드의 수를 입력을 받음 """ def __init__(self, num_heads, d_model, dropout=0.1): super().__init__() assert d_model % num_heads == 0 self.d_k = d_model // num_heads self.num_heads = num_heads self.q_linear = nn.Linear(d_model, d_model) self.k_linear = nn.Linear(d_model, d_model) self.v_linear = nn.Linear(d_model, d_model) self.output_linear = nn.Linear(d_model, d_model) self.attention = Attention() self.dropout = nn.Dropout(dropout) def forward(self, query, key, value, mask=None): batch_size = query.size(0) q = self.q_linear(query).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2) k = self.k_linear(key).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2) v = self.v_linear(value).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2) # 어텐션 적용 x, attn = self.attention(q, k, v, mask=mask, dropout=self.dropout) # concat 후 output lienear 적용 output = x.transpose(1, 2).contiguous().view(batch_size, -1, self.num_heads * self.d_k) output = self.output_linear(output) return output
- Position-wise Feed-Forward Network
- 각 헤드의 정보를 섞어주는 역활
class PositionwiseFeedForward(nn.Module): def __init__(self, d_model, d_ff, dropout=0.1): super().__init__() self.w_1 = nn.Linear(d_model, d_ff) self.w_2 = nn.Linear(d_ff, d_model) self.dropout = nn.Dropout(dropout) self.activation = nn.GELU() def forward(self, x): output = self.w_1(x) output = self.activation(output) output = self.dropout(output) output = self.w_2(output) return output
-
Stacking Transformer Layer
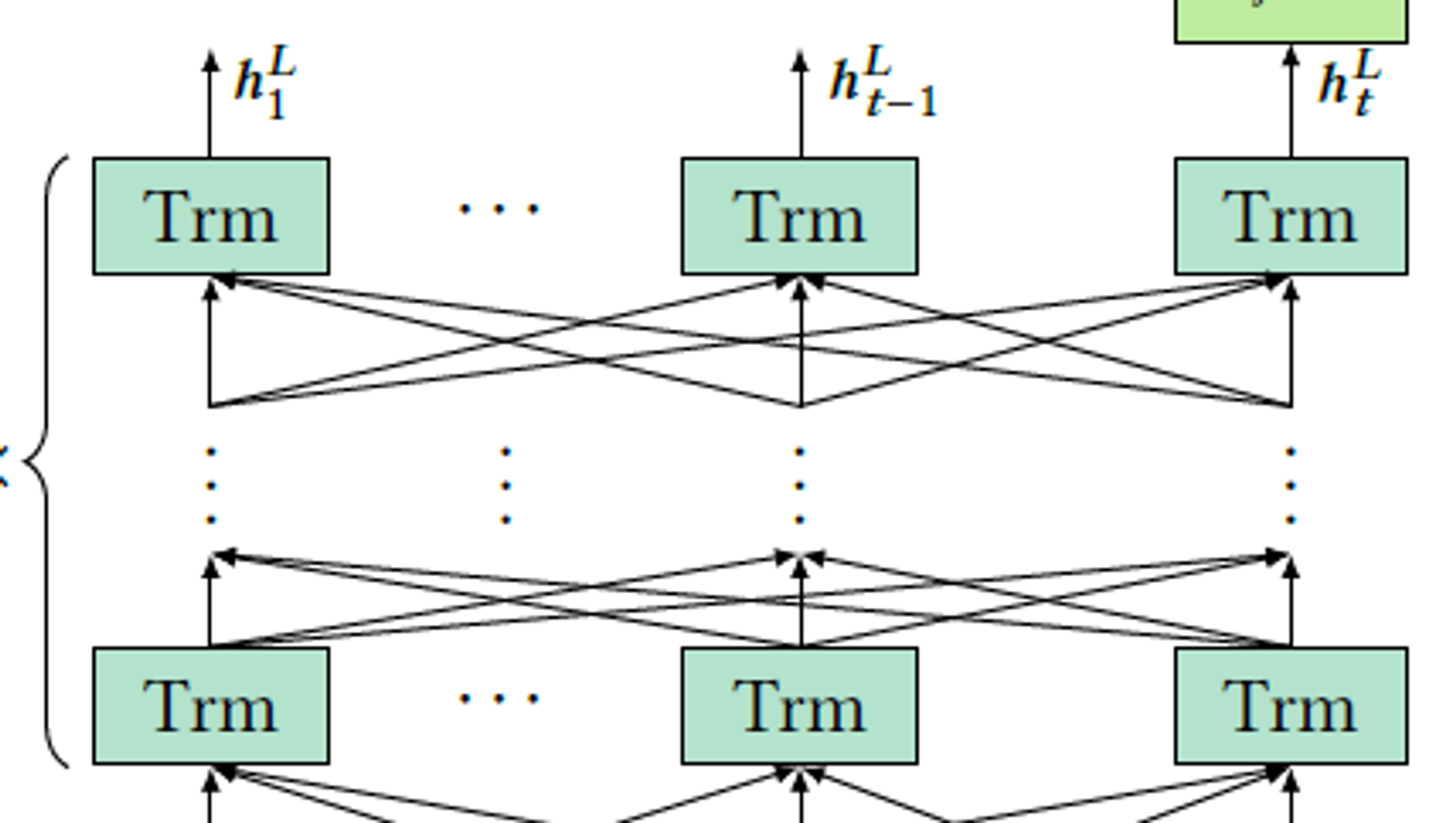
3.4 Embedding Layer
we use the learnable positional embeddings instead of the fixed sinusoid embedding
class PositionalEmbedding(nn.Module): def __init__(self, max_len, d_model) -> None: super().__init__() # 학습이 가능한 형태의 positional embedding self.pe = nn.Embedding(max_len, d_model) """ pos_encoding = torch.zeros(position, d_model).to(device) pos = torch.arange(0, position).float().unsqueeze(1) _2i = torch.arange(0, d_model, 2).float() pos_encoding[:, 0::2] = torch.sin(pos / 10000 ** (_2i / d_model)) pos_encoding[:, 1::2] = torch.cos(pos / 10000 ** (_2i / d_model)) self.pos_encoding = pos_encoding.unsqueeze(0) self.pos_encoding.requires_grad = False """ def forward(self, x): batch_size = x.size(0) return self.pe.weight.unsqueeze(0).repeat(batch_size, 1, 1)
class TokenEmbedding(nn.Embedding): def __init__(self, vocab_size, embedding_size=512): super().__init__(vocab_size, embedding_size, padding_idx=0)
class BERTembedding(nn.Module): def __init__(self, vocab_size, embedding_size, max_len, dropout=0.1): super().__init__() self.token = TokenEmbedding(vocab_size, embedding_size) self.position = PositionalEmbedding(max_len, embedding_size) self.dropout = nn.Dropout(dropout) self.embedding_size = embedding_size def forward(self, sequence): output = self.token(sequence) + self.position(sequence) output = self.dropout(output) return output
3.5 Output
$$ P(u) = softmax(GELU(h^L_tW^P+b^p)E^T + b^O) $$
class BERT4Rec(nn.Module): def __init__(self, max_len, num_items, n_layers, num_heads, hidden, dropout): super().__init__() vocab_size = num_items + 1 self.hidden = hidden self.embedding = BERTembedding(vocab_size, hidden, max_len, dropout) self.encoder_blocks = nn.ModuleList([ EncoderBlock(hidden, num_heads, hidden * 4, dropout) for _ in range(n_layers) ]) self.out = nn.Linear(hidden, num_items + 1) def forward(self, x): mask = (x > 0).unsqueeze(1).repeat(1, x.size(1), 1).unsqueeze(1) x = self.embedding(x) for encoder in self.encoder_blocks: x = encoder.forward(x, mask) output = self.out(x) return output
3.6 Model Learning
-
Cloze 학습 방법
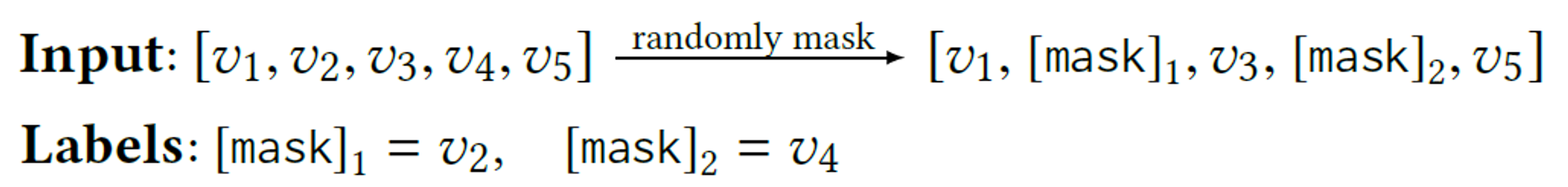
class BertTrainDataset(Dataset): def __init__(self, u2seq, max_len, mask_prob, mask_token, num_items, rng): self.u2seq = u2seq self.users = sorted(self.u2seq.keys()) self.max_len = max_len self.mask_prob = mask_prob self.mask_token = mask_token self.num_items = num_items self.rng = rng def __len__(self): return len(self.users) def __getitem__(self, index): user = self.users[index] seq = self._getseq(user) tokens = [] labels = [] for s in seq: prob = self.rng.random() if prob < self.mask_prob: prob /= self.mask_prob if prob < 0.8: tokens.append(self.mask_token) elif prob < 0.9: tokens.append(self.rng.randint(1, self.num_items)) else: tokens.append(s) labels.append(s) else: tokens.append(s) labels.append(0) tokens = tokens[-self.max_len:] labels = labels[-self.max_len:] mask_len = self.max_len - len(tokens) tokens = [0] * mask_len + tokens labels = [0] * mask_len + labels return torch.LongTensor(tokens), torch.LongTensor(labels) def _getseq(self, user): return self.u2seq[user]z
3.7 Discussion
- SASRec
- 시퀀스의 각 위치에 대한 다음 아이템을 예측
- BERT4Rec은 Cloze 목표를 사용하여 시퀀스의 마스킹된 아이템을 예측
- CBOW & SG
- CBOW : 컨텍스트의 모든 단어 벡터의 평균을 사용하여 목표 단어를 예측
- SG : 하나를 제외한 모든 아이템을 마스킹
- BERT
- 대용량 말뭉치를 이용한 문장 표현 모델
- BERT4Rec : 세그먼트 임베딩 제거
4. EXPERIMENTS